3D face recognition: a survey
Abstract
3D face recognition has become a trending research direction in both industry and academia. It inherits advantages from traditional 2D face recognition, such as the natural recognition process and a wide range of applications. Moreover, 3D face recognition systems could accurately recognize human faces even under dim lights and with variant facial positions and expressions, in such conditions 2D face recognition systems would have immense difculty to operate. This paper summarizes the history and the most recent progresses in 3D face recognition research domain. The frontier research results are introduced in three categories: pose-invariant recognition, expression-invariant recognition, and occlusion-invariant recognition. To promote future research, this paper collects information about publicly available 3D face databases. This paper also lists important open problems.
3D 얼굴 인식은 산업계와 학계 모두에서 유행하는 연구 방향이되었습니다.
자연 인식 프로세스 및 광범위한 응용 프로그램과 같은 기존 2D 얼굴 인식의 장점을 계승합니다.
더욱이 3D 얼굴 인식 시스템은 어두운 조명 아래에서도 다양한 얼굴 위치와 표정으로 사람의 얼굴을 정확하게 인식 할 수 있습니다.
이러한 조건에서 2D 얼굴 인식 시스템은 작동하기가 매우 어려울 것입니다.
이 논문은 3D 얼굴 인식 연구 분야의 역사와 가장 최근의 진전을 요약합니다.
프론티어 연구 결과는 자세 불변 인식, 표현 불변 인식, 폐색 불변 인식의 세 가지 범주로 소개됩니다.
향후 연구를 촉진하기 위해 이 논문은 공개적으로 사용 가능한 3D 얼굴 데이터베이스에 대한 정보를 수집합니다.
이 문서는 또한 중요한 미해결 문제를 나열합니다.
Introduction
Face recognition has been a hot research area for its wide range of applications [1]. In human identifcation scenarios, facial metrics are more naturally accessible than many other biometrics, such as iris, finger print, and palm print [2]. Face recognition is also highly valuable in human computer interaction, access control, video surveillance, and many other applications.
얼굴 인식은 광범위한 응용 분야에서 뜨거운 연구 분야였습니다 [1].
인간 식별 시나리오에서 안면 메트릭은 홍채, 지문 및 장문 [2]과 같은 다른 많은 생체 인식보다 자연스럽게 접근 할 수 있습니다.
얼굴 인식은 인간 컴퓨터 상호 작용, 액세스 제어, 비디오 감시 및 기타 여러 응용 프로그램에서도 매우 중요합니다.

Although 2D face recognition research made significant progresses in recent years, its accuracy is still highly depended on light conditions and human poses [3, 4]. When the light is dim or the face poses are not properly aligned in the camera view, the recognition accuracy will suffer. The fast evolution of 3D sensors reveals a new path for face recognition that could overcome the fundamental limitations of 2D technologies. The geometric information contained in 3D facial data could substantially improve the recognition accuracy under conditions that are diffcult for 2D technologies [5]. Many researchers have turned their focuses to 3D face recognition and made this research area a new trend. A general work flow for 3D face recognition is shown in Fig. 1. The work flow could be decomposed into two phases and five stages. In the training phase, 3D face data are acquired and then preprocessed to obtain “clean” 3D faces. Ten the data are processed by feature extraction algorithms to find the features that could be used to differentiate faces. The features of each face are then stored into the feature database. In the testing phase, the target face goes through the acquisition, preprocessing, and feature extraction stages that are identical to the stages in the training phase. In the feature matching stage, the features of the target face are compared with the faces stored in the feature database and calculate the match scores. When a match score is suffciently high, we would claim that the target face is recognized.
2D 얼굴 인식 연구가 최근 몇 년 동안 상당한 진전을 이루었지만 그 정확도는 여전히 빛의 조건과 사람의 포즈에 크게 좌우됩니다 [3, 4].
빛이 어둡거나 얼굴 포즈가 카메라 뷰에서 제대로 정렬되지 않으면 인식 정확도가 떨어집니다.
3D 센서의 빠른 진화는 2D 기술의 근본적인 한계를 극복 할 수있는 얼굴 인식의 새로운 경로를 보여줍니다.
3D 얼굴 데이터에 포함 된 기하학적 정보는 2D 기술이 어려운 조건에서 인식 정확도를 크게 향상시킬 수 있습니다 [5].
많은 연구자들이 3D 얼굴 인식에 초점을 맞추고이 연구 분야를 새로운 트렌드로 만들었습니다.
3D 얼굴 인식의 일반적인 작업 흐름은 그림 1에 나와 있습니다.
작업 흐름은 2 단계와 5 단계로 나눌 수 있습니다.
훈련 단계에서 3D 얼굴 데이터를 수집 한 다음 "깨끗한"3D 얼굴을 얻기 위해 전처리합니다.
10 개의 데이터는 특징 추출 알고리즘으로 처리되어 얼굴을 구별하는 데 사용할 수있는 특징을 찾습니다.
그러면 각 얼굴의 특징이 특징 데이터베이스에 저장됩니다.
테스트 단계에서 대상 얼굴은 학습 단계의 단계와 동일한 획득, 전처리 및 특징 추출 단계를 거칩니다.
피처 매칭 단계에서는 대상 얼굴의 피처를 피처 데이터베이스에 저장된 얼굴과 비교하고 일치 점수를 계산합니다.
일치 점수가 충분히 높으면 대상 얼굴이 인식되었다고 주장합니다.
3D face acquisition 3D 얼굴 획득

The acquisition of 3D face samples involves special hardware equipments, which could be categorized as active acquisition systems and passive acquisition systems according to the technologies used. The active acquisition systems actively emit non-visible light, e.g. infrared laser beams, to illuminate the target human face. Ten the systems measure the refection to determine the shape features of the target face. According to the different types of illumination methods, the active acquisition systems could be further categorized as triangulation-based and structured light based. As shown in Fig. 2a, Minolta vivid scanner is an example of triangulation-based 3D scanning system. The scanner measures the emitting and the receiving angles of the laser beam, and then use triangulation methods to determine the exact point of refection. As the laser beam scanning through the face, a precise map is formed by calculating and grouping many refection would require the target man to hold still for several minutes before a 3D face map could be acquired [7]. Therefore this technology is infeasible for the 3D video recording. Compared with the triangulation based systems, the structured light based systems are more popular in consumer level 3D face acquisition. Figure 2b shows a Microsoft Kinect, which emits a light pattern, such as a light grid, to the target face. It then measures the deformation of the light pattern to calculate the surface shape. The structured light based systems offer much faster measurements than the triangulation based systems. However, the structured light measurements often contain holes and artifacts so that the acquired 3D face data are less precise than the triangulation data [8]. Figure 2c shows a Bumblebee XB3, which is a passive acquisition system [9]. It contains several cameras that are placed apart from each other. The system matches points observed from different camera and calculates the exact 3D location of the matched point [10]. The set of the matched points forms the 3D face. Systems like Bumblebee XB3 are often called stereo imaging systems. Such systems relied on good visible light conditions and usually deliver less precise 3D face data than active 3D face acquisition systems.
3D 얼굴 샘플 획득에는 사용된 기술에 따라 능동 수집 시스템과 수동 수집 시스템으로 분류 될 수있는 특수 하드웨어 장비가 포함됩니다.
능동 수집 시스템은 가시적이지 않은 빛을 능동적으로 방출합니다.
적외선 레이저 빔, 대상 사람의 얼굴을 비춘 후, 그 시스템은 반사를 측정하여 대상 얼굴의 모양 특징을 결정합니다.
다양한 유형의 조명 방법에 따라 능동 수집 시스템은 삼각 측량 기반 및 구조화 된 조명 기반으로 더 분류 될 수 있습니다.
그림 2a에서 볼 수 있듯이 Minolta 생생한 스캐너(Minolta vivid scanner)는 삼각 측량 기반 3D 스캐닝 시스템의 예입니다.
스캐너는 레이저 빔의 방출 및 수신 각도를 측정한 다음 삼각 측량 방법을 사용하여 정확한 반사 지점을 결정합니다.
얼굴을 통해 레이저 빔을 스캐닝함에 따라 많은 반사를 계산하고 그룹화하여 정밀한지도가 형성되기 때문에 3D 얼굴지도를 획득하기 전에 표적 사람이 몇 분 동안 가만히 있어야합니다 [7].
따라서 이 기술은 3D 비디오 녹화에 적합하지 않습니다.
삼각 측량 기반 시스템과 비교하여 구조화된 조명 기반 시스템은 소비자 수준의 3D 얼굴 획득에서 더 많이 사용됩니다.
[7] Zaharescu A, Boyer E, Varanasi K, Horaud R (2009) Surface feature detection and description with applications to mesh matching. In: Proc. IEEE Conf. on Comput
그림 2b는 라이트 그리드와 같은 라이트 패턴을 대상 얼굴에 방출하는 Microsoft Kinect를 보여줍니다.
그런 다음 조명 패턴의 변형을 측정하여 표면 모양을 계산합니다.
구조화된 조명 기반 시스템은 삼각 측량 기반 시스템보다 훨씬 빠른 측정을 제공합니다.
그러나 구조화 된 빛 측정은 종종 구멍과 인공물을 포함하므로 획득한 3D 얼굴 데이터가 삼각 측량 데이터보다 덜 정확합니다 [8].
[8] Kittler J, Hilton MH (2005) A survey of 3d imaging, modelling and recognition approachest. In: IEEE Conference on Computer Vision and Pattern Recognition Workshops. pp 114–114
그림 2c는 수동 수집 시스템인 Bumblebee XB3를 보여줍니다 [9].
서로 떨어져 배치된 여러 카메라가 포함되어 있습니다.
이 시스템은 다른 카메라에서 관찰 된 포인트를 매칭하고 매칭 포인트의 정확한 3D 위치를 계산합니다 [10].
일치하는 점 세트가 3D면을 형성합니다.
Bumblebee XB3와 같은 시스템을 종종 스테레오 이미징 시스템이라고합니다.
이러한 시스템은 우수한 가시 광선 조건에 의존했으며 일반적으로 활성 3D 얼굴 수집 시스템보다 덜 정확한 3D 얼굴 데이터를 제공합니다.
[9] Bennamoun M, Guo Y, Sohel F (2015) Feature selection for 2d and 3d face recognition. Research Gate, vol 17
Preprocessing
Acquired 3D face data cannot be directly used as the inputs of feature extraction algorithms because the data contain the human faces, but also many distracting features such as hair, ear, neck, eye glasses, and jeweleries. It is true that when us human beings identify each other, these features could be helpful. However, computers are not as intelligent as us at least for now. Features like hair, eye glasses, and jeweleries could be changed from time to time. Ear and neck features are not reliably identifiable for different head poses. These features could be misleading to the current state-of-the-art 3D face recognition algorithms and therefore should be removed before feature extraction. The first step of preprocessing is to detect the position and orientation of human face. Geometric transformations are used to “turn” the human face to directly against the camera axis. Ten the preprocessing uses the help from clearly identifiable facial parts such as nose to isolate the human face area out from areas of the distracting features. Tis operation is called segmentation. The preprocessed facial data samples are often interpreted in three model formats: depth image, point cloud, and mesh, as shown in Fig. 2. Note that the three model formats are not one to one corresponding to the three popular 3D scanners. They are formats to represent 3D face data.
획득한 3D 얼굴 데이터는 사람의 얼굴뿐 아니라 머리카락, 귀, 목, 안경, 보석류와 같은 방해가 되는 특징도 포함하기 때문에 특징 추출 알고리즘의 입력으로 직접 사용할 수 없습니다.
우리 인간이 서로를 식별 할 때 이러한 특징이 도움이 될 수 있다는 것은 사실입니다.
그러나 컴퓨터는 적어도 현재로서는 우리만큼 지능적이지 않습니다.
머리카락, 안경, 보석류와 같은 기능은 수시로 변경 될 수 있습니다.
귀와 목의 특징은 다른 머리 자세에서 안정적으로 식별 할 수 없습니다.
이러한 특징은 현재의 최신 3D 얼굴 인식 알고리즘에서는 오해 할 수 있으므로 특징 추출 전에 제거해야합니다.
전처리의 첫 번째 단계는 사람 얼굴의 위치와 방향을 감지하는 것입니다.
기하학적 변형은 사람의 얼굴을 카메라 축에 직접 "회전"하는 데 사용됩니다.
그러고 난 후에 전처리는 코와 같이 명확하게 식별 가능한 얼굴 부분의 도움을 사용하여 방해가 되는 특징 영역에서 사람의 얼굴 영역을 분리합니다.
이 작업을 세분화(segmentation)라고합니다.
전처리 된 안면 데이터 샘플은 그림 2와 같이 깊이 이미지, 포인트 클라우드 및 메시의 세 가지 모델 형식으로 해석되는 경우가 많습니다.
세 가지 모델 형식은 널리 사용되는 세 가지 3D 스캐너에 해당하는 일대일이 아닙니다.
3D 얼굴 데이터를 나타내는 형식입니다.
Feature extraction, feature database, and feature matching 기능 추출, 기능 데이터베이스 및 특징 일치
The most straightforward school of feature extraction is to take the entire face as a single feature vector, which is called the global approach [12]. In this approach, the entire face is stored in the database. In the feature matching stage, the target face is compared with faces in database using statistical classifcation functions [9]. Opposed to the global approach, the component based approach focuses on the local facial characteristics such as nose and eyes. It uses graph operators to extract the nose and eyes part and store these local features in the database. When a target face is inputed for recognition, the component based approach first extract the corresponding parts from the target faces and then searching the matched set of parts from the feature database [13]. There are hybrid approaches that combine the features used by the global approaches and the local approaches. With more computational cost, the hybrid approach could achieve better recognition accuracy [14].
가장 간단한 특징 추출 방법은 전체 얼굴을 하나의 특징 벡터로 취하는 것인데,이를 글로벌 접근 방식이라고합니다 [12].
이 접근 방식에서는 전체 얼굴이 데이터베이스에 저장됩니다.
특징 매칭 단계에서는 통계적 분류 함수를 사용하여 대상 얼굴을 데이터베이스의 얼굴과 비교합니다 [9].
글로벌 접근 방식과 달리 구성 요소 기반 접근 방식은 코와 눈과 같은 국소 얼굴 특성에 중점을 둡니다.
그래프 연산자를 사용하여 코와 눈 부분을 추출하고 이러한 로컬 기능을 데이터베이스에 저장합니다.
인식을 위해 대상 얼굴이 입력되면 컴포넌트 기반 접근 방식은 먼저 대상 얼굴에서 해당 부분을 추출한 다음 특징 데이터베이스에서 일치하는 부분 집합을 검색합니다 [13].
글로벌 접근 방식과 로컬 접근 방식에서 사용하는 기능을 결합하는 하이브리드 접근 방식이 있습니다.
더 많은 계산 비용으로 하이브리드 접근 방식은 더 나은 인식 정확도를 달성 할 수 있습니다 [14].
Methodology

In 3D face recognition system, the selection of feature extraction and matching methods is very important. Both global and local approach have been extensively investigated in the literature and summarized in Table 1.
3D 얼굴 인식 시스템에서 특징 추출 및 매칭 방법의 선택은 매우 중요합니다.
글로벌 및 로컬 접근 방식 모두 문헌에서 광범위하게 조사되었으며 표 1에 요약되어 있습니다.
Performance metrics 성능 메트릭
This paper proposes the following indications about the performance measures for 3D face recognition tasks. The notation used for evaluation is as follows:
• TP—the number of samples for the prediction of the positive class as the positive class.
• FN—the number of samples of positive class is predicted to be negative class.
• FP—the number of samples whose negative class is predicted as positive class.
• TN—the number of samples of negative class is predicted to be negative class. Among them, True and False indicate correct and wrong classifcation, Positive and Negative samples.
본 논문에서는 3 차원 얼굴 인식 작업의 성능 측정에 대해 다음과 같은 지표를 제안한다. 평가에 사용되는 표기법은 다음과 같습니다.
• TP-포지티브 클래스를 포지티브 클래스로 예측하기위한 샘플 수입니다.
• FN-양성 등급의 샘플 수는 음성 등급으로 예측됩니다.
• FP-네거티브 클래스가 포지티브 클래스로 예측되는 샘플 수.
• TN-네거티브 클래스의 샘플 수는 네거티브 클래스로 예측됩니다. 그중 참과 거짓은 정확하고 잘못된 분류, 양성 및 음성 샘플을 나타냅니다.
The calculation metrics are as follows: Accuracy refers to the ratio between the number of samples correctly classifed by the classifier and the total number of samples for a given test data set, which reflects the judging ability of the classifier to the entire sample. In other words, it can determine the positive value and the negative value. Error rate is the opposite of accuracy rate. Precision refers to the proportion of true positive samples in the samples judged as positive by the classifier, that is, how many of all samples judged as positive by the classifier are true positive samples. Recall refers to the proportion of the positive samples correctly judged by the classifier in the total positive samples, that is, how many of all the positive samples are classified by the classifier as positive samples. Fbeta-score is the harmonic mean of precision and recall
계산 메트릭은 다음과 같습니다.
정확도는 분류기에 의해 올바르게 분류 된 샘플 수와 주어진 테스트 데이터 세트에 대한 총 샘플 수 간의 비율을 의미하며, 이는 전체 샘플에 대한 분류기의 판단 능력을 반영합니다.
즉, 양의 값과 음의 값을 결정할 수 있습니다.
오류율은 정확도 비율과 반대입니다.
정밀도는 분류기에 의해 양성으로 판정된 샘플에서 참 양성 샘플의 비율, 즉 분류기에 의해 양성으로 판정된 모든 샘플 중 참 양성 샘플이 몇 개인지를 나타냅니다.
재현율은 총 양성 샘플에서 분류자가 올바르게 판단한 양성 샘플의 비율, 즉 분류기에 의해 양성 샘플로 분류 된 모든 양성 샘플의 수를 나타냅니다.
Fbeta-score는 정밀도와 재현율의 조화 평균입니다.
(1)
(2)
The value of β (β > 0) reflects the relative importance of precision and recall in performance evaluation. When β = 1, the commonly used F1 (F measure) value indicates that precision is as important as recall.
The value of F1 (F measure) is also known as Balanced f-score. When both accuracy and recall are high, the value of F1 (F measure) is also high. The rest of this paper is organized as follows: “History of face recognition research” section introduces significant research results of 3D face recognition in an chronicle order. Tis help establish a bird-view on this research area. “Domain research problems” section analyzes current researches and summarize them into domain research problems. “Research on 3D face databases” section collects the up-to-date information about public 3D face databases, which could facilitate future researches. “Research on pose-invariant 3D face recognition” section reviews the technologies that could mitigate the pose variation problem for 3D face recognition. “Research on expression—invariant 3D face recognition” section surveys the technologies that could accurately recognize human faces in different expressions such as laughing or crying, using 3D face information. “Research on occlusion—invariant 3D face recognition” section reviews the 3D face recognition technologies that could work when the target faces are partially blocked. “Open problems and perspectives” section suggest significant problems that are still waiting to be solved in 3D face recognition area. “Conclusions and discussion” section concludes this paper.
β 값 (β> 0)은 성능 평가에서 정밀도와 재현율의 상대적 중요성을 반영합니다.
β = 1 인 경우 일반적으로 사용되는 F1 (F 측정 값) 값은 정밀도가 재현율만큼 중요함을 나타냅니다.
F1 (F 측정 값)의 값은 균형 잡힌 f- 점수라고도합니다.
정확도와 재현율이 모두 높으면 F1 (F 측정) 값도 높습니다.
이 논문의 나머지 부분은 다음과 같이 구성되어 있습니다.
“안면 인식 연구의 역사”섹션에서는 3D 얼굴 인식의 중요한 연구 결과를 연대기 순서로 소개합니다.
이것은 이 연구 분야에 대한 조감도를 확립하는 데 도움이됩니다.
"도메인 연구 문제"섹션에서는 현재 연구를 분석하고 이를 도메인 연구 문제로 요약합니다.
"3D 얼굴 데이터베이스에 대한 연구"섹션에서는 향후 연구를 촉진 할 수있는 공개 3D 얼굴 데이터베이스에 대한 최신 정보를 수집합니다.
“포즈 불변 3D 얼굴 인식 연구”섹션에서는 3D 얼굴 인식을위한 자세 변형 문제를 완화 할 수있는 기술을 검토합니다.
“표현 연구-불변 3D 얼굴 인식”섹션에서는 3D 얼굴 정보를 사용하여 웃음이나 울음과 같은 다양한 표정에서 사람의 얼굴을 정확하게 인식 할 수있는 기술을 조사합니다.
"폐색에 대한 연구-불변 3D 얼굴 인식"섹션에서는 대상 얼굴이 부분적으로 차단되었을 때 작동 할 수있는 3D 얼굴 인식 기술을 검토합니다.
"개방형 문제 및 관점"섹션에서는 3D 얼굴 인식 영역에서 아직 해결을 기다리고있는 중요한 문제를 제안합니다.
"결론 및 논의"섹션이이 문서를 마칩니다.
History of face recognition research 얼굴 인식 연구의 역사
Research in face recognition can be dated back to 1960s [15]. From 1964 to 1966 Woodrow W. Bledsoe, along with Helen Chan and Charles Bisson of Panoramic Research, researched programming computers to recognize human faces. Their program asks the administrator to locate the eyes, ears, nose and mouth in the photo. Ten, the reference data can be use comparison with the distance and measures. However, because of inconvenience, this work has not received much recognition. Peter Hart at the Stanford Research Institute continued this research, and found optimistic results when using a set of images instead of a set of feature points. Since then, there have been many researches following on this subject and a substantial amount of efforts have been made to find the optimal face recognition method. In the 1970s, Goldstein, Harmon, and Lesk used 21 specific subjective markers such as hair color and lip thickness to automatically identify human faces. The attempt obtained good recognition accuracy. However, the feature measurement and locationing are manually calculated. It is impractical to apply this method to many faces. In 1991, Turk and Pentland proposed a method of using principal component analysis (PCA) to handle face data [16]. Tis is called the eigenface algorithm which is already become a golden standard for face recognition. Later, inspired by eigenface, a large number of such algorithms were proposed [17–19].
얼굴 인식에 관한 연구는 1960 년대로 거슬러 올라갑니다 [15].
1964 년부터 1966 년까지 Woodrow W. Bledsoe는 Panoramic Research의 Helen Chan 및 Charles Bisson과 함께 인간의 얼굴을 인식하는 프로그래밍 컴퓨터를 연구했습니다.
그들의 프로그램은 관리자에게 사진에서 눈, 귀, 코 및 입을 찾아달라고 요청합니다.
그런 후에, 참조 데이터는 거리 및 측정 값과 비교하여 사용할 수 있습니다.
그러나 불편함으로 인해이 작품은 많은 인정을받지 못했다.
Stanford Research Institute의 Peter Hart는이 연구를 계속했으며 일련의 특징점 대신 이미지 집합을 사용할 때 낙관적 인 결과를 발견했습니다.
그 이후로 이 주제에 대한 많은 연구가 있었고 최적의 얼굴 인식 방법을 찾기 위해 많은 노력을 기울였습니다.
1970 년대에 Goldstein, Harmon 및 Lesk는 머리카락 색깔과 입술 두께와 같은 21 개의 특정 주관적 마커를 사용하여 사람의 얼굴을 자동으로 식별.
시도는 좋은 인식 정확도를 얻었습니다.
그러나 기능 측정 및 위치 지정은 수동으로 계산됩니다.
이 방법을 많은면에 적용하는 것은 비현실적입니다.
1991 년에 Turk와 Pentland는 얼굴 데이터를 처리하기 위해 PCA (주성분 분석)를 사용하는 방법을 제안했습니다 [16].
이것은 이미 얼굴 인식의 황금 표준이 된 고유 얼굴 알고리즘이라고합니다.
나중에 eigenface에서 영감을 받아 많은 알고리즘이 제안되었습니다 [17-19].
In 1997, Christoph von der Malsburg designed a system that can identify people in photos when the photos are not clear [20]. Followed this work, the research of face recognition diverged into two paths. Face recognition by 3D view is proposed and implemented in systems such as Polar and FaceIt [21].
1997 년 Christoph von der Malsburg는 사진이 선명하지 않을 때 사진 속 사람을 식별 할 수있는 시스템을 설계했습니다 [20].
이 연구에 이어 얼굴 인식 연구는 두 가지 경로로 나뉘어졌습니다.
3D 뷰에 의한 얼굴 인식은 Polar 및 FaceIt과 같은 시스템에서 제안되고 구현됩니다 [21].
Although 2D face recognition has achieved considerable success, but the accuracy is still significantly affected by changes in pose and illumination conditions [14, 22]. Many researchers have turned to 3D face recognition because its potential capabilities to overcome the inherent limitations and drawbacks of 2D face recognition. Moreover, the geometric information provided by 3D face data may result in higher recognition accuracy than the 2D case when the pose and illumination conditions are the same [3, 4].
2D 얼굴 인식은 상당한 성공을 거두었지만 정확도는 여전히 포즈 및 조명 조건의 변화에 따라 크게 영향을 받습니다 [14, 22].
많은 연구자들은 2D 얼굴 인식의 고유 한 한계와 단점을 극복 할 수있는 잠재적 기능 때문에 3D 얼굴 인식으로 전환했습니다.
또한 3D 얼굴 데이터가 제공하는 기하학적 정보는 포즈와 조명 조건이 같을 때 2D 경우보다 인식 정확도가 높아질 수 있습니다 [3, 4].
In the late 1980s, [23] used curvature-based methods to test on a small 3D face database, and reached 100% recognition accuracy. In 1996, Gordon’s face recognition experiments showed that combining frontal and side views can improve the recognition accuracy [24]. After that, more and more 3D face recognition research has been proposed, because of the increasing availability of 3D scanning equipments (mainly based on laser and structured light technology).
1980년대 후반에 [23]은 곡률 기반 방법(curvature-based methods)을 사용하여 작은 3D 얼굴 데이터베이스에서 테스트했으며 인식 정확도가 100 %에 도달했습니다.
1996 년 Gordon의 얼굴 인식 실험은 정면과 측면 뷰를 결합하여 인식 정확도를 높일 수 있음을 보여주었습니다 [24].
그 후 3D 스캐닝 장비 (주로 레이저 및 구조 광 기술 기반)의 가용성이 증가함에 따라 점점 더 많은 3D 얼굴 인식 연구가 제안되었습니다.
In 2012, deep learning was first used to analyze and process three-dimensional face images for face recognition [25]. Compared with the traditional method, Deep Convolutional Neural Networks (DCNN) has a great advantage in the processing of image and video, whereas Recurrent Neural Network (RNN) also shows a very good performance in processing continuous data such as voice and text [26]. By using deep learning to train large-scale face datasets, the recognition accuracy of 2d face recognition has been significantly improved [27]. The method of deep learning needs to large datasets to learn face features and be able to depict rich internal information of data. Large-scale 2D face datasets can be obtained from the Internet. Compared 2D face dataset, training discriminative deep features for 3D face recognition is very difficult due to the lack of large-scale 3D face datasets [27]. In order to solve this problem, Kim et al. [27] proposed using the existing trained 2D face model, and adjust a small amount of 3D face datasets to 3D surface matching. Also, [28] proposed a method for generating a large corpus of labeled 3D face identities and their multiple instances for training and a protocol for merging the most challenging existing 3D datasets for testing. They also proposed the first deep CNN model designed specifically for 3D face recognition and trained on 3.1 million 3D facial scans of 100,000 identities. The proposed training and test datasets are several orders of magnitude larger than previously existing 3D datasets reported in the literature. Based on the 3D datasets, FR3DNet algorithm has been proposed and achieved great accuracy in closed and open world recognition scenarios [28].
2012년에는 얼굴 인식을 위해 3 차원 얼굴 이미지를 분석하고 처리하는 데 딥러닝이 처음 사용되었습니다 [25].
기존 방법에 비해 DCNN (Deep Convolutional Neural Networks)은 이미지 및 비디오 처리에 큰 이점이있는 반면, RNN (Recurrent Neural Network)은 음성 및 텍스트와 같은 연속 데이터 처리에서도 매우 우수한 성능을 보여줍니다.
딥러닝을 사용하여 대규모 얼굴 데이터 세트를 학습함으로써 2D 얼굴 인식의 인식 정확도가 크게 향상되었습니다 [27].
딥러닝 방법은 얼굴 특징을 학습하고 데이터의 풍부한 내부 정보를 표현할 수있는 대용량 데이터 세트가 필요합니다.
대규모 2D 얼굴 데이터 세트는 인터넷에서 얻을 수 있습니다.
2D 얼굴 데이터 세트와 비교할 때, 3D 얼굴 인식을 위한 차별적인 심층 기능을 훈련하는 것은 대규모 3D 얼굴 데이터 세트가 없기 때문에 매우 어렵습니다 [27]. 이 문제를 해결하기 위해 Kim et al. [27]은 기존의 학습된 2D 얼굴 모델을 사용하여 제안하고, 소량의 3D 얼굴 데이터 셋을 3D 표면 매칭으로 조정합니다.
또한, [28]는 레이블이 지정된 3D 얼굴 ID와 이들의 다중 인스턴스를 교육용으로 대량 생성하는 방법과 가장 까다로운 기존 3D 데이터 세트를 테스트 용으로 병합하는 프로토콜을 제안했습니다.
그들은 또한 3D 얼굴 인식을 위해 특별히 설계된 최초의 딥 CNN 모델을 제안하고 100,000 개의 신원에 대한 310 만 개의 3D 얼굴 스캔에 대해 학습.
제안된 교육 및 테스트 데이터 세트는 문헌에 보고된 기존 3D 데이터 세트보다 몇 배 더 큽니다.
3D 데이터 세트를 기반으로 FR3DNet 알고리즘이 제안되었으며 폐쇄형 및 개방형 세계 인식 시나리오에서 뛰어난 정확도를 달성했습니다 [28].
In [14], many identification techniques were surveyed. Face recognition can be divided into three categories based on feature extraction methods used in the identification process: global approach, component-based approach and hybrid approach. In the global approach, the entire face is used as a single feature vector for feature classification. The component-based approach mainly analyzes the local facial features such as nose and eyes. The hybrid approach uses both global and local features. The hybrid approach is very effective when the face is frontal and the expression does not change.
[14]에서는 많은 식별 기술이 조사되었습니다.
얼굴 인식은 식별 프로세스에 사용되는 특징 추출 방법에 따라 글로벌 접근 방식, 구성 요소 기반 접근 방식 및 하이브리드 접근 방식(global approach, component-based approach and hybrid approach)의 세 가지 범주로 나눌 수 있습니다.
1.글로벌 접근 방식에서는 전체 얼굴이 특징 분류를 위한 단일 특징 벡터로 사용됩니다.
2.구성 요소 기반 접근 방식은 주로 코와 눈과 같은 국소 얼굴 특징을 분석합니다.
3.하이브리드 접근 방식은 전역 및 로컬 기능을 모두 사용합니다.
하이브리드 방식은 얼굴이 정면이고 표정이 변하지 않을 때 매우 효과적입니다.
Domain research problems 도메인 연구 문제
Compared with other popular biometric identification technologies such as finger print, iris and retina based recognition, face recognition can identify a person at greater distance. Therefore, it can be applied to various application scenarios such as crowd monitoring and border control. In many of these application scenarios, the 2D face images cannot be accurately recognized due to variations in facial expressions, head pose, occlusion and other factors. Any of these adversary factors could lead to a sharp decrease in recognition effciency [29].
지문, 홍채 및 망막 기반 인식과 같은 다른 인기있는 생체 인식 기술과 비교하여 얼굴 인식은 더 먼 거리에있는 사람을 식별 할 수 있습니다.
따라서 군중 모니터링 및 국경 통제(crowd monitoring and border control)와 같은 다양한 응용 시나리오에 적용될 수 있습니다.
이러한 많은 응용 시나리오에서 2D 얼굴 이미지는 얼굴 표정, 머리 자세, 가림 및 기타 요인의 변화로 인해 정확하게 인식되지 않습니다.
이러한 적대적인 요인은 인식 효율성의 급격한 감소로 이어질 수 있습니다 [29].
In 1999, Blanz and Vetter proposed the 3D deformation model (3DMM) synthesis technique and then use this model for 3D face recognition [30]. However, due to the technical limit of the 3D scanning technology at the time, their 3D deformation model was reconstructed from 2D images. It takes a large amount of computation to reconstruct the 3D model. Many researchers agree that 3DMM play an important role in face recognition, but the computational complexity of the reconstruction process hinders its applicability [14, 31–33].
1999년에 Blanz와 Vetter는 3D 변형 모델 (3DMM) 합성 기술을 제안한 다음이 모델을 3D 얼굴 인식에 사용했습니다 [30].
그러나 당시 3D 스캐닝 기술의 기술적 한계로 인해 3D 변형 모델은 2D 이미지에서 재구성되었습니다.
3D 모델을 재구성하려면 많은 양의 계산이 필요합니다.
많은 연구자들은 3DMM이 얼굴 인식에서 중요한 역할을한다는 데 동의하지만 재구성 프로세스의 계산 복잡성으로 인해 적용 가능성이 떨어집니다 [14, 31–33].
In 2003, Blanz and Vetter proposed to combine 3DMM with 2D image matching technology in order to recognize faces with various head orientations [34]. Unlike [30], their algorithm automatically evaluates all 3D scene parameters, including the position and orientation of the head. Through this new initialization process, the robustness and reliability of the face recognition system is significantly improved. It is noteworthy that the 2D image synthesized 3D facial model is a compromise when fast 3D scanning technology is not available. As soon as people can directly scan 3D face data, models like 3DMM is no longer in active research. In 2003, Wu et al. [35] prosposed 3D face recognition by extracting multiple horizontal profiles from the facial range data. One pitfall of this method is, the recognition accuracy would decrease significantly when the head pose changes. In [1], Zhang compared the methods and algorithms for 3D face recognition under pose variations, and tests the maximum angle that can be recognized when pose changes. For example, when the face is registered from front and the face model is extracted using the LBP algorithm in [29], an acceptable recognition accuracy could be retained at a maximal face rotation of 60°. Our paper also compares the influence of 2D images and 3D models on recognition performance under changes in head pose. Experiments have shown that 3D models are better tolerant to pose changes than 2D models. We summarized this type of research in “Research on pose-invariant 3D face recognition” section.
2003년 Blanz와 Vetter는 다양한 머리 방향을 가진 얼굴을 인식하기 위해 3DMM과 2D 이미지 매칭 기술을 결합할 것을 제안했습니다 [34].
[30]과 달리 알고리즘은 머리의 위치와 방향을 포함한 모든 3D 장면 매개 변수를 자동으로 평가합니다.
이 새로운 초기화 프로세스를 통해 얼굴 인식 시스템의 견고성과 신뢰성이 크게 향상되었습니다.
빠른 3D 스캐닝 기술을 사용할 수 없는 경우 2D 이미지 합성 3D 얼굴 모델이 절충안이라는 점은 주목할 만합니다.
사람들이 3D 얼굴 데이터를 직접 스캔 할 수있게되면 3DMM과 같은 모델은 더 이상 연구가 진행되지 않습니다.
2003년에 Wu et al. [35]는 얼굴 범위 데이터에서 여러 개의 수평 프로파일을 추출하여 3D 얼굴 인식을 제안했습니다.
이 방법의 한 가지 함정은 머리 자세가 변경 될 때 인식 정확도가 크게 감소한다는 것입니다.
[1]에서 Zhang은 포즈 변화에 따른 3D 얼굴 인식 방법과 알고리즘을 비교하고 포즈 변화시 인식 할 수 있는 최대 각도를 테스트했습니다.
예를 들어 [29]의 LBP 알고리즘을 사용하여 얼굴을 정면에서 등록하고 얼굴 모델을 추출하면 최대 60 °의 얼굴 회전에서 허용 가능한 인식 정확도를 유지할 수 있습니다.
우리 논문은 또한 머리 자세의 변화에서 인식 성능에 대한 2D 이미지와 3D 모델의 영향을 비교합니다.
실험에 따르면 3D 모델이 2D 모델보다 포즈 변경에 더 잘 견디는 것으로 나타났습니다.
이러한 유형의 연구는“포즈 불변 3D 얼굴 인식 연구”섹션에서 요약했습니다.
Chua et al. [36] use point signatures in 3D facial recognition. In order to deal with changes in facial expressions, only the rigid part of the face (below the forehead and above the nose) is used. The point signature is also used to locate the reference point in the standardized face model. The images used in the experiment were obtained from the different expressions of 6 subjects, and recognition rate was 100%. The principal component analysis (PCA) method explored by Hesher et al. [37] uses different numbers of feature vectors and image sizes. The image data set used has 37 subjects, each containing 6 different facial expressions. Using multiple images in the gallery improves the recognition accuracy [38]. Moreno et al. [39] segment the 3D face model using Gaussian curvature and then created a feature vector based on the segmented region for the recognition. This method achieved 78% recognition accuracy in a dataset of 420 faces from 60 people with different facial expressions. Our paper summarizes this type of research in “Research on expression—invariant 3D face recognition” section.
Chua et al. 3D 얼굴 인식에서 포인트 시그니처(point signatures)을 사용합니다.
얼굴 표정의 변화에 대처하기 위해 얼굴의 딱딱한 부분 (이마 아래, 코 위) 만 사용합니다.
포인트 시그니처는 표준화 된 얼굴 모델에서 참조 포인트를 찾는데도 사용됩니다.
실험에 사용 된 이미지는 6 명의 피험자의 다양한 표정에서 얻은 것으로 인식률은 100 %였다.
Hesher et al.에 의해 탐색 된 주성분 분석 (PCA) 방법. [37]은 다양한 수의 특징 벡터와 이미지 크기를 사용합니다.
사용 된 이미지 데이터 세트에는 각각 6 개의 서로 다른 얼굴 표정을 포함하는 37 개의 피사체가 있습니다.
갤러리에서 여러 이미지를 사용하면 인식 정확도가 향상됩니다 [38].
Moreno et al. 가우스 곡률을 이용하여 3 차원 얼굴 모델을 분할한 다음 인식을 위해 분할된 영역을 기반으로 특징 벡터를 생성합니다.
이 방법은 서로 다른 표정을 가진 60 명의 얼굴 420 명의 데이터 세트에서 78 %의 인식 정확도를 달성했습니다.
우리 논문은 "표현에 관한 연구-불변 3D 얼굴 인식"섹션에서 이러한 유형의 연구를 요약합니다.
When the face is partially blocked, the recognition accuracy would suffer. In [40, 41], Martinez et al. divided the face model into small areas and proposed a probabilistic approach to match each area locally. The matching results are then combined for the face recognition. Colombo and Cusano [42] propose to recover the blocked part through algorithms and then use the recovered face data in recognition. This method is also useful when people have decorative objects on their face such as scarf, hat, or eye glasses. Our paper summarizes this type of research in “Research on occlusion—invariant 3D face recognition” section. In this paper, we will review the latest solutions and the results achieved from the three classes of face recognition research introduced in sections above. Because these researches are all based on some 3D face datasets. In the following sections, we will frstly summarize the current publicly available 3D face database, including the data type of each database, the number of people being collected, the number of scanned images collected, as well as variations in pose, expression, and occlusion.
얼굴이 부분적으로 가려지면 인식 정확도가 떨어집니다.
[40, 41]에서 Martinez et al. 얼굴 모델을 작은 영역으로 나누고 각 영역을 지역적으로 일치시킬 확률적 접근 방식을 제안했습니다.
그런 다음 일치하는 결과가 얼굴 인식을 위해 결합됩니다.
Colombo와 Cusano [42]는 알고리즘을 통해 차단된 부분을 복구한 다음 복구 된 얼굴 데이터를 인식에 사용할 것을 제안합니다.
이 방법은 사람들이 스카프, 모자 또는 안경과 같은 장식용 물건을 얼굴에 가지고있을 때도 유용합니다.
우리의 논문은 "폐색에 대한 연구-불변 3D 얼굴 인식(“Research on occlusion—invariant 3D face recognition” section)"섹션에서 이러한 유형의 연구를 요약합니다.
본 논문에서는 위 섹션에서 소개 한 세 가지 유형의 얼굴 인식 연구에서 얻은 최신 솔루션과 결과를 검토합니다.
이러한 연구는 모두 일부 3D 얼굴 데이터 세트를 기반으로하기 때문입니다.
다음 섹션에서는 각 데이터베이스의 데이터 유형, 수집되는 사람 수, 수집 된 스캔 이미지 수, 포즈, 표현 및 폐색의 변형을 포함하여 현재 공개적으로 사용 가능한 3D 얼굴 데이터베이스를 처음으로 요약합니다.
Research on 3D face databases 3D 얼굴 데이터베이스 연구

There are many large-scale 2D face databases in the world. These databases provide a common platform to evaluate and compare 2D face recognition algorithms. 3D face databases are less common and smaller in scale. Before 2004, there were few publicly available 3D face databases. In recent years, many research institutes have established different kinds of 3D face databases to test and evaluate their own methods for 3D face recognition. Listed below are some of the published 3D databases (see Table 1) that compare different types of data formats, the number of faces, the number of models, and the types of scanning devices. Tables 2, 3 and 4 show the 3D databases constructed specifically for recognition algorithms that could adapt to the expression variation, the pose variation, and the occlusion variation.
세계에는 많은 대규모 2D 얼굴 데이터베이스가 있습니다.
이러한 데이터베이스는 2D 얼굴 인식 알고리즘을 평가하고 비교할 수있는 공통 플랫폼을 제공합니다.
3D 얼굴 데이터베이스는 덜 일반적이고 규모가 작습니다.
2004년 이전에는 공개적으로 사용 가능한 3D 얼굴 데이터베이스가 거의 없었습니다.
최근 몇 년 동안 많은 연구 기관에서 3D 얼굴 인식을 위한 자체 방법을 테스트하고 평가하기위해 다양한 종류의 3D 얼굴 데이터베이스를 구축했습니다.
다음은 다양한 유형의 데이터 형식, 얼굴 수, 모델 수 및 스캔 장치 유형을 비교하는 게시된 3D 데이터베이스 (표 1 참조) 중 일부입니다.
표 2, 3 및 4는 표현 변형, 포즈 변형 및 폐색 변형에 적응할 수있는 인식 알고리즘을 위해 특별히 구성된 3D 데이터베이스를 보여줍니다.

The FRGC [43] database (as shown in Fig. 3c) has tremendous influence on the development of 3D face recognition algorithms. It is widely accepted as a standard reference database to evaluate the performance of 3D face recognition algorithms. The pictures in the database are all 640 * 480 pixel 3D images, scanned by the Minolta Vivid 3D scanner with corresponding RGB texture information. The data was divided into the training set FRGC v1.0, which consisted of 943 scanned images of 273 individuals and the training set (FRGC v2.0), which contains 4007 scanned images of 466 individuals with additional expression tags such as anger, happiness, sadness, surprise and disgust.
FRGC [43] 데이터베이스 (그림 3c)는 3D 얼굴 인식 알고리즘 개발에 엄청난 영향을 미칩니다.
3D 얼굴 인식 알고리즘의 성능을 평가하기위한 표준 참조 데이터베이스로 널리 사용됩니다.
데이터베이스의 사진은 모두 해당 RGB 텍스처 정보와 함께 Minolta Vivid 3D 스캐너로 스캔 한 640 * 480 픽셀 3D 이미지입니다.
데이터는 273 명의 개인 스캔 이미지 943 개로 구성된 트레이닝 세트 FRGC v1.0과 분노, 행복 ,슬픔, 놀라움과 혐오감.과 같은 추가 표현 태그가있는 466 명의 개인 스캔 이미지 4007 개가 포함 된 트레이닝 세트 (FRGC v2.0)로 나뉩니다.
BU-3DFE is a 3D face database built specifically for the algorithm development on the expression-invariant face recognition [44] (as shown in Fig. 3a). There are 2500 3D scans from 100 individuals using the stereo photography technique. Tis database contains 6 types of expressions: anger, happiness, sadness, surprise, disgust, and fear. Each type of expression is further tagged with four different levels.
BU-3DFE는 표정 불변 얼굴 인식 [44]에 대한 알고리즘 개발을 위해 특별히 구축된 3D 얼굴 데이터베이스입니다 (그림 3a 참조).
스테레오 사진 기술을 사용하는 100 명의 개인으로부터 2500 개의 3D 스캔이 있습니다.
이 데이터베이스에는 분노, 행복, 슬픔, 놀라움, 혐오감, 두려움의 6 가지 표현이 있습니다.
각 유형의 표현식에는 네가지 레벨이 추가로 태그 지정됩니다.
As shown in Fig. 3b, Bosphorus [45] database contains 3D face images with variations on expressions, head poses, and different types of occlusion. Tis database is based on 4666 3D scan images of 105 individuals and was scanned using an Inspeck Mega Capturor II 3D scanner.
그림 3b에서 볼 수 있듯이 Bosphorus [45] 데이터베이스에는 표정, 머리 포즈 및 다양한 유형의 폐색이있는 3D 얼굴 이미지가 포함되어 있습니다.
이 데이터베이스는 105 명의 개인 4666 3D 스캔 이미지를 기반으로하며 Inspeck Mega Capturor II 3D 스캐너를 사용하여 스캔되었습니다.
As shown in Fig. 3e, the ND-2006 dataset [46] was the largest 3D face dataset at the time of publication, and it was also a superset of FRGC v2.0. It contains 13,450 3D scan images with 6 different expression tags (neutral, happy, sad, surprised, disgusted, etc.) and was scanned using a Minolta Vivid 910 range scanner. There were a total of 888 different people had been scanned. Each person had been scanned multiple times. The most scanned person appeared 63 times in the database.
그림 3e에서 볼 수 있듯이 ND-2006 데이터 세트 [46]는 발행 당시 가장 큰 3D 얼굴 데이터 세트였으며 FRGC v2.0의 상위 세트이기도합니다.
여기에는 6 개의 다른 표현 태그 (중립, 행복, 슬픔, 놀란, 혐오 등)가있는 13,450 개의 3D 스캔 이미지가 포함되어 있으며 Minolta Vivid 910 범위 스캐너를 사용하여 스캔되었습니다.
총 888 명의 사람이 스캔되었습니다.
각 사람은 여러 번 스캔되었습니다. 가
장 많이 스캔 된 사람은 데이터베이스에 63 번 나타났습니다.
The Texas 3D Face Recognition Database (Texas 3DFRD) [47], shown in Fig. 3d, is a set of 1149 pairs of face texture descriptions and scanned images using the MU-2 stereo imaging system. The database includes 105 adult subjects.
그림 3d에 표시된 Texas 3D 얼굴 인식 데이터베이스 (Texas 3DFRD) [47]는 1149 쌍의 얼굴 텍스처 설명과 MU-2 스테레오 이미징 시스템을 사용하여 스캔 한 이미지 세트입니다. 데이터베이스에는 105 명의 성인 피험자가 포함되어 있습니다.
BJUT-3D is a large Chinese Face 3D Face Dataset [44] (as shown in Fig. 3f) which includes 500 Chinese people as the subjects. 250 women and 250 men registered their 3D face data in the database. High-resolution human 3D facial data are scanned using a CyberWare 3030 RGB/PS laser scanner.
BJUT-3D는 500 명의 중국인을 대상으로하는 큰 Chinese Face 3D Face Dataset [44] (그림 3f 참조)입니다.
250 명의 여성과 250 명의 남성이 데이터베이스에 3D 얼굴 데이터를 등록했습니다.
CyberWare 3030 RGB / PS 레이저 스캐너를 사용하여 고해상도 인간 3D 얼굴 데이터를 스캔합니다.
As shown in Fig. 3g, the CASIA dataset [48] was tested in 2004 using a non-contact 3D digitizer Minolta Vivid 910 range scanner for 4624 scans of 123 people. The data set not only considers single changes in pose, expression, and lighting, but also changes in expression under the same lighting and pose changes under the same expression.
그림 3g에서 볼 수 있듯이 CASIA 데이터 세트 [48]는 2004 년 비접촉식 3D 디지타이저 Minolta Vivid 910 범위 스캐너를 사용하여 123 명의 4624 스캔에 대해 테스트되었습니다.
데이터 세트는 포즈, 표현 및 조명의 단일 변경뿐만 아니라 동일한 조명에서 표현의 변화와 동일한 표현에서 포즈 변경도 고려합니다.
3D-TEC (3D Twins Expression Challenge (3D-TEC) Data Set) [49], this dataset contains 3D facial scans of 107 pairs of twins, that is 214 people, each with a smile and a neutral expression for a total of 428 scans. Although this data set is ten times smaller than the FRGC v2.0 data set, it is still very representative, because it includes twins with different expressions. Tis database will help promote the development of 3D face recognition technology.
3D-TEC (3D 쌍둥이 표현 챌린지 (3D-TEC) 데이터 세트) [49],이 데이터 세트에는 107 쌍의 쌍둥이, 즉 214 명의 3D 얼굴 스캔이 포함되어 있으며, 각각 미소를 지으며 총 428 명의 스캔에 대해 중립적인 표정을지었습니다.
이 데이터 세트는 FRGC v2.0 데이터 세트보다 10 배 작지만 다른 표현을 가진 쌍둥이를 포함하기 때문에 여전히 매우 대표적입니다.
이 데이터베이스는 3D 얼굴 인식 기술의 개발을 촉진하는 데 도움이됩니다.

In contrast to 2D face images, 3D models contains the geometry information and are insensitive to pose and lighting changes [50, 51]. There are two kinds of acquisition techniques for acquiring 3D face models: the active acquisition technologies and the passive acquisition technologies. Examples of the active acquisition technologies include triangulation and structured light. The most typical passive acquisition system is a stereo camera [9]. In active acquisition techniques, such as the Minolta Vivid scanners (shown in Fig. 4a), triangulation technology is used. The scanner emits laser light on the face and then uses the camera to record the image of the light spot. Once the center pixel of the point is calculated, the position of the laser spot is determined by the triangle formed by the laser spot, camera, and laser emitter. The effective range of the triangulation technique could be a few meters with the accuracy of several millimeters. However, the triangulation process could be time-consuming. The scanner has to reconstruct the 3D face model point by point. Using structured light technology, such as the Microsoft Kinect (shown in Fig. 4b), the scanner projects a pattern onto the face surface, and then a camera captures the pattern deformed by the face contour. The shape of the face is calculated based on the deformation of the pattern. Structured light can acquire 3D face data in real time, but the acquired data may contain a large number of holes and artifacts. For a typical passive acquisition system, such as the Bumblebee XB3 (shown in Fig. 4c), the scanner uses two (or more) cameras to take pictures for the face from different angles. The system uses algorithms to match feature points in different pictures and then calculates the exact position of the feature points with the triangulation algorithm. Multiple feature points are calculated simultaneously and then used to reconstruct the 3D face model [10, 52]. The main pitfall of the stereoscopic system is the relatively low resolution of the reconstructed 3D face scans.
2D 얼굴 이미지와 달리 3D 모델은 형상 정보를 포함하며 포즈 및 조명 변경에 민감하지 않습니다 [50, 51].
3D 얼굴 모델을 획득하기위한 획득 기술에는 능동 획득 기술과 수동 획득 기술의 두 가지 종류가 있습니다.
능동 획득 기술의 예로는 삼각 측량 및 구조 광이 있습니다.
가장 일반적인 수동 수집 시스템은 스테레오 카메라입니다 [9].
Minolta Vivid 스캐너 (그림 4a 참조)와 같은 능동적 획득 기술에서는 삼각 측량 기술이 사용됩니다.
스캐너는 얼굴에 레이저 광을 방출 한 다음 카메라를 사용하여 광점의 이미지를 기록합니다.
포인트의 중심 픽셀이 계산되면 레이저 스폿의 위치는 레이저 스폿, 카메라 및 레이저 이미 터에 의해 형성된 삼각형에 의해 결정됩니다.
삼각 측량 기법의 유효 범위는 몇 밀리미터의 정확도로 몇 미터가 될 수 있습니다.
그러나 삼각 측량 과정은 시간이 많이 걸릴 수 있습니다. 스캐너는 3D 얼굴 모델을 포인트별로 재구성해야합니다.
Microsoft Kinect (그림 4b 참조)와 같은 구조화 된 조명 기술을 사용하여 스캐너는 얼굴 표면에 패턴을 투사 한 다음 카메라가 얼굴 윤곽에 의해 변형 된 패턴을 캡처합니다.
얼굴의 모양은 패턴의 변형에 따라 계산됩니다.
구조 광은 실시간으로 3D 얼굴 데이터를 수집 할 수 있지만 수집 된 데이터에는 많은 수의 구멍과 인공물이 포함될 수 있습니다.
Bumblebee XB3 (그림 4c 참조)과 같은 일반적인 수동 수집 시스템의 경우 스캐너는 두 대 이상의 카메라를 사용하여 서로 다른 각도에서 얼굴 사진을 찍습니다.
시스템은 알고리즘을 사용하여 다른 그림의 특징점을 일치시킨 다음 삼각 분할 알고리즘을 사용하여 특징점의 정확한 위치를 계산합니다.
여러 특징점을 동시에 계산 한 다음 3D 얼굴 모델을 재구성하는 데 사용합니다 [10, 52].
입체 시스템의 주요 함정은 재구성 된 3D 얼굴 스캔의 상대적으로 낮은 해상도입니다.
3D face recognition algorithms have different performances on different 3D face databases. Many methods are implemented on a specific 3D face database, and performance on other databases may vary.
3D 얼굴 인식 알고리즘은 3D 얼굴 데이터베이스에 따라 성능이 다릅니다. 많은 방법이 특정 3D 얼굴 데이터베이스에서 구현되며 다른 데이터베이스의 성능은 다를 수 있습니다.
Research on pose‑invariant 3D face recognition 자세 불변 3D 얼굴 인식 연구

As shown in Fig. 5, in 3D face recognition, the change of head poses can substantially affect the accuracy of 3D face recognition. Many 3D face recognition systems rely on the front face model. Once the head is not upright or the face orientation is rotated away from the front-facing pose, the system would have difficulty to match the face scan with the preset face models.
그림 5에서 보는 바와 같이 3D 얼굴 인식에서 머리 자세의 변화는 3D 얼굴 인식의 정확도에 큰 영향을 미칠 수 있습니다.
많은 3D 얼굴 인식 시스템은 전면 모델에 의존합니다.
머리를 똑바로 세우지 않거나 얼굴 방향이 전면 포즈에서 멀어지면 시스템은 얼굴 스캔을 사전 설정된 얼굴 모델과 일치시키는 데 어려움을 겪습니다.

As early as 2003, Song et al. [54] proposed a 3D face recognition method which could stand with large head defection. The method depends on the geometric information of the feature points on the face to “adjust” the head pose in the scanned image. Figure 6 briefly shows the extraction of facial feature points, the determination of the head position, and the process of recognition. First, the maximum and minimum curvature points are automatically extracted using the geometric information of the face. These points are composed of the bump points and the nasal peak point (NPP). In order to find the exact position of the head and the defection angle of the head from the input 3D head image, They proposed the Error Compensated SVD (EC-SVD) algorithm to minimize the least square error and then compensate in the established 3D normalized space. For each axis, the pose is optimized from the angle acquired by the SVD method, thereby restoring the face model to the frontal angle.
2003년부터 Song et al. [54]는 큰 머리 탈락에도 견딜 수 있는 3D 얼굴 인식 방법을 제안했다.
이 방법은 스캔한 이미지에서 머리 자세를 "조정"하기 위해 얼굴에있는 특징점의 기하학적 정보에 따라 다릅니다.
그림 6은 얼굴 특징점 추출, 머리 위치 결정 및 인식 과정을 간략하게 보여줍니다.
먼저 얼굴의 기하학적 정보를 이용하여 최대 및 최소 곡률점을 자동으로 추출합니다.
이 지점은 범프 지점과 비강 피크 지점 (NPP)으로 구성됩니다.
입력 된 3D 머리 영상에서 머리의 정확한 위치와 머리의 결손 각도를 찾기 위해 최소 제곱 오차를 최소화 한 후 정규화 된 3D 공간에서 보상하는 Error Compensated SVD (EC-SVD) 알고리즘을 제안했습니다.
각 축에 대해 SVD 방법으로 얻은 각도에서 포즈를 최적화하여 얼굴 모델을 정면 각도로 복원합니다.
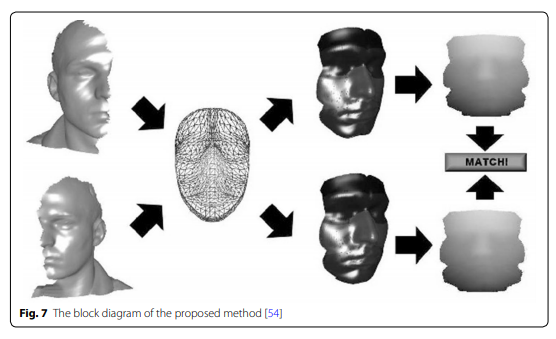
Passalis et al. [55] proposed a method to use face symmetry to resolve the pose variation problem. Tis method uses wavelet biometric signatures which is also used in the landmark detection algorithms proposed in [56]. The signatures allows a matching for the face symmetry to compensate the pose variation (as shown in Fig. 7). Experiments show that this method is suitable for practical scenarios because it requires no manual intervention and the whole process is fully automatic. Moreover, this method is good at handling extreme pose changes such as a nearly 90° head rotation and leaving only one side of the face to the front.
Passalis et al. 포즈 변화 문제를 해결하기 위해 얼굴 대칭을 사용하는 방법을 제안했다.
이 방법은 [56]에서 제안 된 랜드 마크 탐지 알고리즘에서도 사용되는 웨이블릿 생체 서명을 사용한다.
시그니처는 포즈 변화를 보상하기 위해 얼굴 대칭에 대한 매칭을 허용합니다 (그림 7 참조).
실험에 따르면 이 방법은 수동 개입이 필요하지 않고 전체 프로세스가 완전 자동이기 때문에 실제 시나리오에 적합합니다.
또한 이 방법은 거의 90 ° 머리 회전과 같은 극심한 포즈 변화를 처리하고 얼굴의 한쪽 만 앞쪽으로 남겨 두는 데 유용합니다.
[55] Passalis G, Perakis P, Theoharis T, Kakadiaris IA (2011) Perakis: Using facial symmetry to handle pose variations in real-world 3d face recognition. Pattern Anal Mach Intell 33:1938–1951
[56] Perakis P, Passalis G, Theoharis T, Toderici G, Kakadiaris IA (2009) Partial matching
Perakis et al. [56] proposed an algorithm to handle internal occlusion. The algorithm is based on the annotated face model (AFM). The geometry created by the AFM is also invariant in the event of data missing. Therefore, this method deals with incomplete data problems due to pose changes. Verification experiments had been conducted on FRGC v2.0 and can UND. The UND45LR contains a set of scans with each person turns its head 45° away from the frontal orientation. For each person in the scan, the left pose scan belongs to the training set and the right pose scan is considered to be in the testing set. Similarly, the UND60LR marks a collection of side scans with a 60° pose.
Perakis et al. 내부 폐색을 처리하는 알고리즘을 제안했다.
알고리즘은 주석이 달린 얼굴 모델 (AFM)을 기반으로합니다.
AFM에 의해 생성 된 지오메트리는 데이터가 누락 된 경우에도 변하지 않습니다.
따라서 이 방법은 포즈 변경으로 인한 불완전한 데이터 문제를 처리합니다.
검증 실험은 FRGC v2.0에서 수행되었으며 UND 수 있습니다.
UND45LR에는 각 사람이 정면 방향에서 머리를 45 ° 돌리는 스캔 세트가 포함되어 있습니다.
스캔의 각 사람에 대해 왼쪽 포즈 스캔은 훈련 세트에 속하고 오른쪽 포즈 스캔은 테스트 세트에 있는 것으로 간주됩니다.
마찬가지로 UND60LR은 60 ° 포즈로 측면 스캔 모음을 표시합니다.
In [13], a new 3D surface representation method, namely the multi-scale local binary model (MS-LBP) depth map, is proposed. This method is used in conjunction with the shape index (SI) map to increase the significance of the smooth-range surface. Scale Invariant Feature Transform (SIFT) are introduced to extract local features to enhance their robustness to pose variations. The Rank-one recognition rate achieved on the FRGC v2.0 database is 96.1%. Since local facial features are used, this method has been shown to be capable of handle partially occluded facial probes.
[13]에서는 새로운 3 차원 표면 표현 방법 인 MS-LBP (Multi-scale Local Binary Model) 깊이 맵이 제안되었다.
이 방법은 형상 지수 (SI) 맵과 함께 사용되어 매끄러운 범위 표면의 중요성을 높입니다.
SIFT (Scale Invariant Feature Transform)가 도입되어 로컬 기능을 추출하여 변형 포즈에 대한 견고성을 향상시킵니다.
FRGC v2.0 데이터베이스에서 달성 한 1 위 인식률은 96.1 %입니다.
국소 안면 특징이 사용되기 때문에이 방법은 부분적으로 가려진 안면 프로브를 처리 할 수있는 것으로 나타났습니다.
[13]Huang D, Zhang G, Ardabilian M, Wang Y, Chen L (2010) 3d face recognition using distinctiveness enhanced facial representations and local feature hybrid matching. In: Biometrics: theory, applications and systems
Berretti et al. [57] uses Scale Invariant Feature Transform (SIFT) key point detection methods to locate feature points in the depth image and find facial curves that connect these key points. The authors use 45° and 60° side scans in the UND database to test their proposal. Since the same organization has collected UND and FRGC v2.0 databases, they have found 39 identical faces between UND’s 45° lateral face and the frontal scan of FRGC v2.0. In addition, there are 33 identical faces in the 60° side scan of the UND, and the frontal face of the FRGC v 2.0 uses the curvature information of the landmark to achieve matching.
Berretti et al. [57]은 SIFT (Scale Invariant Feature Transform) 키 포인트 감지 방법을 사용하여 깊이 이미지에서 특징 포인트를 찾고 이러한 키 포인트를 연결하는 얼굴 곡선을 찾습니다.
저자는 UND 데이터베이스에서 45 ° 및 60 ° 측면 스캔을 사용하여 제안을 테스트합니다.
동일한 조직이 UND 및 FRGC v2.0 데이터베이스를 수집했기 때문에 UND의 45 ° 측면과 FRGC v2.0의 정면 스캔 사이에 39 개의 동일한 얼굴을 발견했음. 또한 UND의 60 ° 측면 스캔에는 33 개의 동일한면 얼굴이 있으며, FRGC v 2.0의 정면은 랜드 마크의 곡률 정보를 사용하여 일치를 달성합니다.
[57] Berretti S, Del Bimbo PPA (2013) Sparse matching of salient facial curves for recognition of 3d faces with missing parts. Forensics Secur 8:374–389
In [58], face models are represented by radial curves. In order to overcome the data missing problem caused by pose variation, they used a statistical model in the radial curve’s shape space. This method works well for recognition and can reach 98.36% recognition accuracy for faces looking downwards at 35°. However, the scanning result from the right side of the face shows that the recognition rate of the right side scan has dropped to 70.49%, while the left side scan has 86.89%. In addition, the limitation of this method is that manual annotation of the nose tip of the side scan is required.
[58]에서 얼굴 모델은 방사형 곡선으로 표시됩니다.
포즈 변화로 인한 데이터 누락 문제를 극복하기 위해 방사형 곡선의 형상 공간에서 통계 모델을 사용했습니다.
이 방법은 인식에 적합하며 35 °에서 아래쪽을 바라 보는 얼굴에 대해 98.36 %의 인식 정확도에 도달 할 수 있습니다.
그러나 얼굴 오른쪽에서 스캔 한 결과 오른쪽 스캔의 인식률이 70.49 %로 떨어졌고 왼쪽 스캔의 경우 86.89 %로 떨어졌습니다.
또한,이 방법의 한계는 측면 스캔의 코끝에 수동 주석이 필요하다는 것입니다.
[58] Drira H, Amor BB, Srivastava A, Daoudi M, Slama R (2013) 3d face recognition under expressions, occlusions, and pose variations. Pattern Anal Mach Intell 35:2270–2283
Mahmood et al. [59] proposed a matching method using nose region extraction to defend against large yaw changes (approximately 60° of yaw axis). In order to realign the face to the frontal orientation, a pre-defned and pre-trained nose model is used. Face surfaces are represented by local shape descriptors. The effectiveness of this method has been evaluated in the GAVADB 3D facial database, which includes both frontal and partially frontal facial scans. Using this method, the recognition accuracies for frontal face scans and partially frontal facial scans are 94% and 90% respectively.
Mahmood et al. [59]은 큰 요 변화 (요 축의 약 60 °)를 방어하기 위해 코 영역 추출을 사용하는 매칭 방법을 제안했습니다.
얼굴을 정면 방향으로 재정렬하기 위해 사전 정의되고 사전 훈련 된 코 모델이 사용됩니다.
면 표면은 로컬 모양 설명 자로 표시됩니다.
이 방법의 효과는 정면 및 부분 정면 안면 스캔을 모두 포함하는 GAVADB 3D 안면 데이터베이스에서 평가되었습니다.
이 방법을 사용하면 정면 얼굴 스캔과 부분 정면 얼굴 스캔의 인식 정확도는 각각 94 %와 90 %입니다.
[59] Mahmood SA, Ghani RF, Kerim AA (2014) 3d face recognition using pose invariant nose region detector. In: Computer science and electronic engineering conference
Ding et al. [60] proposed a PBPR face representation scheme based on the unobstructed facial texture. PBPR can be applied to face images of arbitrary poses, which has greater advantages than other methods. At the same time, they proposed the MtFTL model for learning compact feature transformation between poses.
Ding et al. [60]은 방해받지 않는 얼굴 텍스처를 기반으로 한 PBPR 얼굴 표현 기법을 제안했다.
PBPR은 임의 포즈의 얼굴 이미지에 적용 할 수있어 다른 방법보다 더 큰 장점이 있습니다.
동시에, 그들은 포즈 간의 콤팩트 한 특징 변환을 학습하기위한 MtFTL 모델을 제안했습니다.
[60] Hua WG (2009) Implicit elastic matching with random projections for pose-variant face recognition. In: Comput. Vis. Pattern Recognit. pp 1502–1509
Research on expression—invariant 3D face recognition 표정 연구-불변 3D 얼굴 인식

Human faces have local non-rigid deformation when the expression changes, which reduces the similarity between the scanned face and the trained face models, and thereby reducing the accuracy of the 3D face recognition algorithms [68]. Figure 8 shows the facial shapes of the five typical expressions: the neutral expression, happiness, sadness, surprise and disgust in 2D and 3D.
인간의 얼굴은 표정이 변할 때 국부적으로 비강성 변형을 가지므로 스캔된 얼굴과 학습된 얼굴 모델 간의 유사성이 감소하여 3D 얼굴 인식 알고리즘의 정확도가 떨어집니다 [68].
그림 8은 5 가지 전형적인 표현의 얼굴 형을 보여줍니다 : 중립적 표현, 행복, 슬픔
[68] Al-Osaimi F, Bennamoun M, Mian A (2009) An expression deformation approach to non-rigid 3D face recognition. Int J Comput Vis. 81(3):302–316
3D face recognition methods that can handle the expression changes generally fall into two categories: rigid [4, 69, 70] and non-rigid [71–73]. The rigid method treats the human face as a rigid subject. Such methods are popular in the early days. The main idea is: when the facial expression changes, there are always some facial regions remain unchanged or have little change. These regions are considered as the rigid areas. The features of the rigid areas are extracted and used in face recognition [74]. The most commonly used rigid areas are the nose, eyes, and the area near the forehead. Queirolo and Silva [75] uses the round area around the nose, the ellipse area around the nose, the face area above the nose, and the entire face area to match. The comprehensive four-part score is used to calculate the similarity between two 3D face images. An modified Simulate Annealing Algorithm (SAA) is then used to find the optimal value of the score. This method was tested with the FRGC v2.0 database and achieved a recognition accuracy of 98.4%. Bornak and Rafei [76] uses the nose area for 3D face recognition. The authors proposed to firstly search for the nasal area in the center of the image, and then extract the outline of the diagonal area of the nasal area as a feature. Erdogmus et al. [77] proposed another local feature based method. They divided the face into several parts, and then calculated the similarity of the corresponding parts between two 3D face images. The conditional density is used to transform the face recognition problem into a probability optimization problem. Miao and Krim [78] uses the nearest point alignment and level set method to search for a region where two face images matching with each other and then uses the size of the matching areas as the similarity of two face images. The method based on the rigid area is relatively simple and easy to implement. However, this type of method discards areas affected by expressions and does not use all the information contained in the 3D face data.
표정 변화를 처리 할 수 있는 3D 얼굴 인식 방법은 일반적으로 경직 [4, 69, 70] 및 비 경직 [71-73]의 두 가지 범주로 나뉩니다.
경직된 방법은 인간의 얼굴을 경직된 주제로 취급합니다.
이러한 방법은 초기에 인기가 있습니다.
주요 아이디어는 표정이 변할 때 항상 일부 얼굴 영역이 변하지 않거나 거의 변하지 않는다는 것입니다.
이 영역은 단단한 영역으로 간주됩니다.
단단한 영역의 특징은 추출되어 얼굴 인식에 사용됩니다 [74].
가장 일반적으로 사용되는 딱딱한 부위는 코, 눈, 이마 근처입니다.
Queirolo and Silva [75]는 코 주변의 둥근 영역, 코 주변의 타원 영역, 코 위의 얼굴 영역 및 전체 얼굴 영역을 일치하도록 사용합니다.
포괄적인 네 부분으로 된 점수는 두 3D 얼굴 이미지 간의 유사성을 계산하는 데 사용됩니다.
그런 다음 수정 된 SAA (Simulate Annealing Algorithm)를 사용하여 점수의 최적 값을 찾습니다.
이 방법은 FRGC v2.0 데이터베이스로 테스트되었으며 98.4 %의 인식 정확도를 달성했습니다.
Bornak과 Rafei [76]는 3D 얼굴 인식을 위해 코 부분을 사용합니다.
저자들은 먼저 이미지 중앙의 비강 영역을 검색 한 다음 비강 영역의 대각선 영역의 윤곽을 특징으로 추출 할 것을 제안했습니다.
Erdogmus et al. 또 다른 로컬 특성 기반 방법을 제안했다.
그들은 얼굴을 여러 부분으로 나눈 다음 두 3D 얼굴 이미지 사이의 해당 부분의 유사성을 계산했습니다.
조건부 밀도는 얼굴 인식 문제를 확률 최적화 문제로 변환하는 데 사용됩니다.
Miao and Krim [78]은 가장 가까운 점 정렬 및 레벨 설정 방법을 사용하여 두 얼굴 이미지가 서로 일치하는 영역을 검색 한 다음 일치하는 영역의 크기를 두 얼굴 이미지의 유사성으로 사용합니다.
강성 영역(rigid area)을 기반으로하는 방법은 비교적 간단하고 구현하기 쉽습니다.
그러나 이러한 유형의 방법은 표정의 영향을받는 영역을 버리고 3D 얼굴 데이터에 포함 된 모든 정보를 사용하지 않습니다.
[74] Amor BB, Ardabilian M, Chen L (2008) Toward a regionbased 3d face recognition approach. In: Multimedia and expo, hannover. pp 101–104
The non-rigid method applies the deformation recovery algorithms to the 3D facial scan to counteract the distortion caused by expression variations. Although a good recognition method can be found in both categories, the non-rigid method is more capable of handling 3D face recognition in facial expression variations and can extract richer facial information [73]. In non-rigid classification, the recognition algorithms are divided into two categories: local methods and holistic methods.
비 강성 방법은 3D 안면 스캔에 변형 복구 알고리즘을 적용하여 표정 변화로 인한 왜곡을 상쇄합니다.
두 범주 모두에서 좋은 인식 방법을 찾을 수 있지만, 비 강성 방법은 표정 변화에서 3D 얼굴 인식을 더 잘 처리 할 수 있으며 더 풍부한 얼굴 정보를 추출 할 수 있습니다 [73].
비 강성 분류에서 인식 알고리즘은 로컬 방법과 전체적 방법의 두 가지 범주로 나뉩니다.
Local feature based expression—invariant approaches 로컬 기능 기반 표현-불변 접근
To our best knowledge, the first review of a 3D face recognition systems based on local processing was composed by Chang et al. [4].
우리가 아는 한, 로컬 프로세싱을 기반으로 한 3D 얼굴 인식 시스템에 대한 첫 번째 리뷰는 Chang et al. [4].
Samir et al. proposed a method of comparing facial shapes by the surface curvature [79]. The basic idea is to roughly represent a facial surface with a limited level curve. The curve is extracted from the depth image. In [80], there is a description of the metric for the facial curve calculation. Experimental results show that this method is robust to various expressions.
Samir et al. 표면 곡률에 따라 얼굴 모양을 비교하는 방법을 제안했다 [79].
기본 아이디어는 제한된 수준의 곡선으로 얼굴 표면을 대략적으로 표현하는 것입니다.
커브는 깊이 이미지에서 추출됩니다.
[80]에는 안면 곡선 계산을위한 메트릭에 대한 설명이 있습니다.
실험 결과는 이 방법이 다양한 표현에 강력 함을 보여줍니다.
[79] Samir C, Srivastava A, Daoudi M (2006) Three-dimensional facerecognition using shapes of facial curves. Pattern Anal Mach Intell. 28:1858–1863
[80] Klassen E, Srivastava A, Mio M, Joshi SH (2004) Analysis of planar shapes using geodesic paths on shape spaces. IEEE Trans Pattern Analy Mach Intell 26(3):372–383
Kin-Chung et al. proposed a 3D face recognition system that combines linear discriminant analysis (LDA) and linear support vector machine (LSVM) [81]. This method can obtain the sum of invariants by capturing local characteristics from multiple regions. Ten sub-regions and subsequent feature vectors are extracted from the frontal face image. In addition, the amount of variation is summed using the moving frame technique [82]. LDA and LSVM based on linear optimal fusion rules provide better performance. The performance of the reporting method decreases with the expression increases.
Kin-Chung et al. 선형 판별 분석 (LDA)과 선형 지원 벡터 기계 (LSVM)를 결합한 3D 얼굴 인식 시스템을 제안했습니다 [81].
이 방법은 여러 지역에서 로컬 특성을 캡처하여 불변의 합계를 얻을 수 있습니다.
앞면 이미지에서 10 개의 하위 영역과 후속 특징 벡터가 추출됩니다.
또한 이동 프레임 기법을 사용하여 변동량을 합산합니다 [82].
선형 최적 융합 규칙을 기반으로하는 LDA 및 LSVM은 더 나은 성능을 제공합니다. 식이 증가하면 보고 방법의 성능이 저하됩니다.
[81] Wong KC, Lin YHHNBXZWY (2007) Optimal linear combination of facial regions for improving identifcation performance. Syst Man Cybern B 37:1138–1148
[82] Fels M, Olver PJ (1997) Moving coframes. I. A practical algorithm. Acta Appl Math 51:99–136
Faltemier et al. used 28 best-performing facial sub-regions for 3D facial recognition [83]. To detect the image, a total of 38 sub-regions were extracted, some of which were overlapping. By using an ICP algorithm, each sub-regions in the probe image matches a gallery image region. The highest Rank-one recognition rate reached 90.2% through single-region matching, which promoted the use of fusion strategies. The improved Bordacount fusion method yields an overall 97.2% Rank-one recognition rate. Although the facial information of the image is not complete in some areas of the FRGC v2.0 database, this algorithm still performs well.
Faltemier et al. 3D 얼굴 인식을 위해 28 개의 최고 성능 얼굴 하위 영역을 사용했습니다 [83].
이미지를 감지하기 위해 총 38 개의 하위 영역이 추출되었으며 그중 일부는 겹치는 부분이 있습니다.
ICP 알고리즘을 사용하면 프로브 이미지의 각 하위 영역이 갤러리 이미지 영역과 일치합니다.
단일 지역 매칭을 통해 가장 높은 1 위 인식률은 90.2 %에 도달하여 융합 전략의 사용을 촉진했습니다.
개선된 Bordacount 융합 방법은 전체적으로 97.2 %의 1 위 인식률을 제공합니다.
FRGC v2.0 데이터베이스의 일부 영역에서는 이미지의 얼굴 정보가 완전하지 않지만 이 알고리즘은 여전히 잘 작동합니다.
[83] Faltemier TC, Bowyer KW, Flynn PJ (2008) A region ensemble for 3d face recognition. In: Information forensics and security 3:62–73
In [84], they proposed a mesh-based 3D face recognition method and evaluated it on the Bosphorus database. The surface micro-components are extracted at the salient points of the local neighborhoods, which are respectively detected by the maximum and minimum curvatures, and the final matching score is determined by the two salient points. The experimental results on the Bosphorus dataset highlight the effectiveness of the method and its robustness in facial expression variations.
[84]에서는 메쉬 기반의 3D 얼굴 인식 방법을 제안하고 Bosphorus 데이터베이스에서 평가했습니다.
표면 미세 성분은 최대 및 최소 곡률로 각각 감지되는 지역 이웃의 돌출 지점에서 추출되며 최종 일치 점수는 두 개의 돌출 지점에 의해 결정됩니다. Bosphorus 데이터 세트에 대한 실험 결과는 방법의 효과와 표정 변화에 대한 견고성을 강조합니다.
[84] Li H, Huang PLJ-MMLCD (2011) Expression robust 3d face recognition via mesh-based histograms of multiple order surface diferential quantities. Image Process (ICIP):3053–3056
In [85], the meshSIFT algorithm and its 3D face recognition are proposed. Te salient points are detected as extremum points in a scale space, and the convex points are determined according to the surface normals in the local neighborhoods that depend on the scale. Position the embossments and describe them in the feature vector of the connected histogram containing the tilt angle and shape index. Because this descriptor is captured from a local area, expressions are almost always preserved. They allow the use of the number of matching features as a measure of similarity to perform 3D face recognition with invariant expression. Using the left-right symmetry of the face to expand the set of feature descriptors, matching features can be found even without overlapping.
[85]에서는 meshSIFT 알고리즘과 3 차원 얼굴 인식을 제안하였다.
눈에 띄는 점은 축척 공간에서 극한 점으로 감지되고 볼록 점은 축척에 의존하는 로컬 이웃의 표면 법선에 따라 결정됩니다.
엠보싱을 배치하고 기울기 각도와 모양 인덱스를 포함하는 연결된 히스토그램의 특징 벡터에 설명합니다.
이 설명자는 로컬 영역에서 캡처되기 때문에 표현식은 거의 항상 보존됩니다.
그들은 일치하는 특징의 수를 유사성의 척도로 사용하여 변하지 않는 표정으로 3D 얼굴 인식을 수행 할 수 있습니다.
얼굴의 좌우 대칭을 사용하여 기능 설명자 세트를 확장하면 겹치지 않고 일치하는 기능을 찾을 수 있습니다.
[85] Smeets D, Keustermans J, Vandermeulen D, Suetens P (2013) meshSIFT: Local surface features for 3D face recognition under expression variations and partial data. Comput Vis Image Underst 117:158–69
Berretti and Werghi [86] proposes a 3D face recognition method based on meshDoG key points detector and local GH descriptors, and proposes an original solution to improve the stability of key points and select the most effective features from local descriptors. Experiments have been conducted to evaluate the effectiveness of optimization recommendations for stable key point detection and feature selection. The recognition accuracy was evaluated on the Bosphorus database and the competition results of existing 3D face recognition solutions based on 3D key points are shown.
Berretti and Werghi [86]는 meshDoG 키 포인트 감지기와 로컬 GH 디스크립터를 기반으로 한 3D 얼굴 인식 방법을 제안하고 키 포인트의 안정성을 향상시키고 로컬 디스크립터에서 가장 효과적인 기능을 선택하기위한 독창적 인 솔루션을 제안합니다.
안정적인 키 포인트 감지 및 기능 선택을위한 최적화 권장 사항의 효과를 평가하기위한 실험이 수행되었습니다.
Bosphorus 데이터베이스에서 인식 정확도를 평가하고 3D 핵심 포인트를 기반으로 한 기존 3D 얼굴 인식 솔루션의 경쟁 결과를 보여줍니다.
[86] Berretti S, Werghi N, Del Bimbo A, Pala P (2014) Selecting stable keypoints and local descriptors for person identifcation using 3D face scans. Vis Comput 30(11):1275–92

Tang et al. proposed a local binary model (LBP) based on a 3D facial segmentation scheme [87]. The face surface is divided into 29 sparse areas and 59 dense areas. They used the nearest neighbor to perform 3d face recognition based on classifiers (Table 5).
Tang et al. 3D 얼굴 분할 방식에 기반한 로컬 바이너리 모델 (LBP)을 제안했습니다 [87].
얼굴 표면은 29 개의 스파 스 영역과 59 개의 조밀한 영역으로 나뉩니다.
가장 가까운 이웃을 사용하여 분류기를 기반으로 3D 얼굴 인식을 수행했습니다 (표 5).
This paper [88] is based on a new 3D facial feature recognition system, namely Angular Radial Signature(ARS), which is extracted from the semi-rigid region of the face, and then use the kernel principal component analysis (KPCA). The ARSs extract medium characteristics to improve the discriminating ability. The medium features are then connected into a single feature vector, which is input into a Support Vector Machine (SVM) to perform face recognition. This method deals with facial expression changes in different individuals by using face scans. They did a lot of experiments on FGRGC v2.0 and SHREC 2008 data sets to get excellent recognition performance.
이 논문 [88]은 얼굴의 반 강체 영역에서 추출한 새로운 3D 얼굴 특징 인식 시스템 인 Angular Radial Signature (ARS)를 기반으로하며 커널 주성분 분석 (KPCA)을 사용합니다.
ARS는 식별 능력을 향상시키기 위해 매체 특성을 추출합니다.
그런 다음 매체 특징은 단일 특징 벡터로 연결되며, 이는 얼굴 인식을 수행하기 위해 SVM (Support Vector Machine)에 입력됩니다.
이 방법은 얼굴 스캔을 사용하여 다른 개인의 표정 변화를 다룹니다.
그들은 뛰어난 인식 성능을 얻기 위해 FGRGC v2.0 및 SHREC 2008 데이터 세트에 대한 많은 실험을 수행했습니다.

Regional Bounding SpheRe descriptors (RBSR) perform effective feature extraction on 3D facial surfaces [89]. In [90] on the application of biometric recognition in 3D face recognition in real life, a new grid SIFT-like algorithm for registration-free 3D face recognition is proposed under expression vatiations, occlusion, and pose changes. The principal curvature-based 3D key point detection algorithm, which can repeatedly recognize the complementary position in the local curvature on a facial scan. Different region based approaches reported so far are summarized in Table 6.
RBSR (Regional Bounding SpheRe descriptor)은 3D 얼굴 표면에서 효과적인 특징 추출을 수행합니다 [89].
[90]에서는 실생활에서 3 차원 얼굴 인식에 생체 인식을 적용하는 것에 대해 표현 변형, 가림, 포즈 변화에 따라 등록이 필요없는 3 차원 얼굴 인식을 위한 새로운 그리드 SIFT 알고리즘이 제안되었다.
얼굴 스캔에서 국부 곡률의 보완 위치를 반복적으로 인식 할 수있는 주요 곡률 기반 3D 키 포인트 감지 알고리즘입니다.
지금까지 보고된 다양한 지역 기반 접근 방식은 표 6에 요약되어 있습니다.
Holistic approaches 전체론적 접근

Tfe following table (Table 7) shows the main holistic approaches for using the deformation model functions in different databases.
다음 표 (표 7)는 다양한 데이터베이스에서 변형 모델 함수를 사용하기위한 주요 전체적인 접근 방식을 보여줍니다.
The method of isometric deformation model belongs to the overall method. In the isometric deformation model method, [96] used the fast-moving method to calculate the geodesic distance of the face surface, established a geodesic distance matrix (GMD), and then used the singular value decomposition (SVD) method to decompose the GMD to obtain the k largest eigenvalues as the shape of the human face descriptor. Miao [97] calculated a set of equal geodesic distance curves for a 3D face surface, and then calculated the evolution vectors between the adjacent two geodesic distance curves. Considering that the evolution vector is easily affected by the deformation of Euclidean space and requires precise face alignment, the author also uses the evolution angle function (EAF) to normalize the evolution vector into a one-dimensional equation. In this way, the comparison problem between two 3D faces is converted into a comparison of two EAF curves. Feng and Krim [98] used the 20 isometric geodesic distance curves from the tip of the nose to represent the human face, and then cut the equal geodesic distance curve into arcs of equal length and then mapped to the Euclidean integral invariant space as face Features to achieve face classification and recognition. This method is tested in the FRGC v2.0 database and the recognition accuracy is 95%.
등각 변형(isometric deformation) 모델의 방법은 전체 방법에 속합니다.
등척 변형(isometric deformation) 모델 방법에서 [96]은 빠르게 움직이는 방법을 사용하여 얼굴 표면의 측지 거리를 계산하고 측지 거리 행렬 (GMD)을 설정 한 다음 SVD (Singular Value Decomposition) 방법을 사용하여 GMD를 분해합니다.
사람의 얼굴 설명 자의 모양으로 k 개의 가장 큰 고유 값을 얻습니다.
Miao [97]는 3D면 표면에 대해 동일한 측지 거리 곡선 세트를 계산한 다음 인접한 두 측지 거리 곡선 사이의 진화 벡터를 계산했습니다.
진화 벡터(Evolution vector)가 유클리드 공간의 변형에 쉽게 영향을 받고 정밀한 얼굴 정렬이 필요하다는 점을 고려할 때, 저자는 진화 벡터를 1 차원 방정식으로 정규화하기 위해 진화 각도 함수 (Evolution angle function,EAF)도 사용합니다.
이러한 방식으로 두 3D얼굴 간의 비교 문제는 두 EAF 곡선의 비교로 변환됩니다.
Feng and Krim [98]은 코 끝에서 20 개의 등각 측지 거리 곡선을 사용하여 사람의 얼굴을 표현한 다음 동일한 측지 거리 곡선을 동일한 길이의 호로 자른 다음 유클리드 적분 불변 공간에 얼굴 특징으로 매핑 얼굴 분류 및 인식을 달성합니다.
이 방법은 FRGC v2.0 데이터베이스에서 테스트되었으며 인식 정확도는 95%입니다.
[96] Smeets D, Fabry T, Hermans J, Vandermeulen D, Suetens P (2010) Fusion of an isometricdeformation modeling approach using spectraldecomposition and a region-based approach using icp for expression invariant 3d face recognition. In: International conference on pattern recognition
[97] Miao S, Krim H (2010) 3d face recognition based on evolution of iso-geodesic distance curves. In: Acoustics, speech, and signal processing. pp 1134–1137
[98] Feng S, Krim H, Kogan IA (2007) 3d face recognition using euclidean integral invariants signature. In: Statistical signal processing, pp 156–160
Berretti and Del Bimbo [99] divide the face surface into a series of equidistant geodesic strips, and then establish a direction index table by measuring the spatial displacement between the equidistant geodesic strips. Finally, compare the orientation index table of the 3D face model to complete face recognition. This form of table based representation greatly reduces the computational complexity, speeds up the search, and is suitable for large-scale face databases. In addition, some scholars use the elastic geodesic between the facial curves to solve the problem of face expression changes and obtain high recognition accuracy [91, 100].
Berretti and Del Bimbo [99]는 면 표면을 등거리 측지선으로 나눈 다음 등거리 측지선 간 공간 변위를 측정하여 방향 인덱스 테이블을 설정합니다.
마지막으로 3D 얼굴 모델의 방향 인덱스 테이블을 비교하여 얼굴 인식을 완료합니다.
이러한 형태의 테이블 기반 표현은 계산 복잡성을 크게 줄이고 검색 속도를 높이며 대규모 얼굴 데이터베이스에 적합합니다.
또한 일부 학자들은 얼굴 표정 변화 문제를 해결하고 높은 인식 정확도를 얻기 위해 얼굴 곡선 사이의 탄성 측지선을 사용합니다 [91, 100].
[99] Berretti S, Del Bimbo PPA (2010) 3d face recognition using isogeodesic stripes. Pattern Anal Mach Intell 32:2162–2177
Mpiperis et al. proposed a geodesic polar coordinatization method for face surfaces [21]. In this way, the internal attributes of the face will not change in the case of isometric deformation, so this representation is suitable for 3D face recognition with expression-invariant. Image classification is done using a PCA classifier and information on colors and shapes is obtained. The experimental results show that the overall performance has been significantly improved by using geodesic polar coordinates.
Mpiperis et al. 면 표면에 대한 측지 극 좌표화(geodesic polar coordinatization) 방법을 제안했습니다 [21].
이런 식으로 등각 변형의 경우 얼굴의 내부 속성이 변경되지 않으므로이 표현은 표현 불변의 3D 얼굴 인식에 적합합니다.
이미지 분류는 PCA 분류기를 사용하여 수행되며 색상 및 모양에 대한 정보를 얻습니다.
실험 결과는 측지 극좌표를 사용하여 전반적인 성능이 크게 향상되었음을 보여줍니다.
Research on occlusion—invariant 3D face recognition 폐색 연구-불변 3D 얼굴 인식




However, obtaining non-cooperative individuals’ face information in an uncontrolled environment may result in certain parts of the face not being captured because hats, sunglasses, eyes or faces may be partially covered by the hair (Figs. 9, 10). The unavailability of this 3D face data is caused by occlusion of external objects. During the scanning process, due to the non-frontal face pose of the detected individual, some parts of the face may not be captured, which results in erroneous data and we call it internal occlusion. Although many researchers are now dealing with the recognition of expression variations, few researchers do the study of the variation of the occlusion. We will give a detailed introduction to the recognition of some researchers in the case of face occlusion in the following content, including the methods they used, the database they used and the recognition effect that was eventually achieved (Table 8).
그러나 통제되지 않은 환경에서 비협조적인 개인의 얼굴 정보를 획득하면 모자, 선글라스, 눈 또는 얼굴이 부분적으로 머리카락으로 가려 질 수 있기 때문에 얼굴의 특정 부분이 캡처되지 않을 수 있습니다 (그림 9, 10).
이 3D 얼굴 데이터를 사용할 수없는 것은 외부 개체의 가림으로 인해 발생합니다.
스캔 과정에서 감지 된 개인의 얼굴이 아닌 포즈로 인해 얼굴의 일부가 캡처되지 않을 수 있으며, 이로 인해 데이터 오류가 발생하고이를 내부 폐색이라고합니다.
현재 많은 연구자들이 표현 변이 인식을 다루고 있지만, 교합 변이에 대한 연구를하는 연구자는 거의 없습니다.
얼굴 가림의 경우 일부 연구자들의 인식에 대해 그들이 사용한 방법, 사용한 데이터베이스, 최종적으로 달성 된 인식 효과를 포함하여 다음 내용에서 자세히 소개합니다 (표 8).
Colombo et al. [42] proposed a brand-new recovery strategy that can effectively recognize 3D faces even when faces are partially occlude by unforeseen and unrelated objects (such as scarves, hats, glasses, etc.). The occlusion region is detected by considering their infuence on the face projection in a suitable face space. Ten, the non-occluded region is used to restore the missing information. Any recognition algorithm can be applied to this recovery strategy. Tis recovery strategy fixes 52 3D faces with all kinds of occlusion and has achieved very good results.
Colombo et al. [42]는 예상치 못한 관련 물체 (예 : 스카프, 모자, 안경 등)에 의해 얼굴이 부분적으로 가려진 경우에도 3D 얼굴을 효과적으로 인식 할 수있는 새로운 복구 전략을 제안했습니다.
폐색 영역은 적절한 얼굴 공간에서 얼굴 투영에 대한 영향을 고려하여 감지됩니다. 그 후, 비 폐쇄 영역은 누락 된 정보를 복원하는 데 사용됩니다.
이 복구 전략에는 모든 인식 알고리즘을 적용 할 수 있습니다. 복구 전략은 모든 종류의 교합으로 52 개의 3D 얼굴을 수정하고 매우 좋은 결과를 얻었습니다.
[42] Colombo A, Cusano C, Schettini R (2006) Detection and restoration of occlusions for 3d face recognition. In: Multimedia and Expo. pp 1541–1544
Alyuz et al. [105] proposed a new 3D face registration and recognition method for partial face regions, which can achieve a good recognition effect in the expression and face occlusion. They proposed a fast and flexible alignment method using average regional models (ARMs) to infer local information by iterating the closest point (ICP) algorithm. Different scores from local regional matchers are derived from local regional matchers are fused to robustly identify probe subjects. In this work, a multi-expression 3D facial database and a Bosphorus 3D face database containing a large number of different types of expressions and realistic face occlusion are used for experimental testing. When face were blocked, a good recognition effect was obtained, and the recognition rate increased from 47.05 to 94.12%.
Alyuz et al. [105]는 표정 및 얼굴 가림에서 우수한 인식 효과를 얻을 수있는 새로운 3D 얼굴 등록 및 부분 얼굴 영역 인식 방법을 제안했다.
그들은 가장 가까운 지점 (ICP) 알고리즘을 반복하여 지역 정보를 추론하기 위해 평균 지역 모델 (ARM)을 사용하는 빠르고 유연한 정렬 방법을 제안했습니다.
지역 지역 일치 자의 다른 점수는 지역 지역 일치 자에서 파생되어 프로브 대상을 강력하게 식별하기 위해 융합됩니다.
이 작업에서는 다양한 유형의 표정과 사실적인 얼굴 폐색을 포함하는 다중 표현 3D 얼굴 데이터베이스와 Bosphorus 3D 얼굴 데이터베이스를 실험 테스트에 사용합니다.
얼굴이 가려지면 좋은 인식 효과를 얻었고 인식률은 47.05에서 94.12 %로 증가했습니다.
[105] Alyuz N, Gokberk B, Akarun L (2008) A 3d face recognition system for expression and occlusion invariance. In: Biometrics: theory, applications and systems
Mayo and Zhang [106] proposed and evaluated a 3D face recognition algorithm based on point cloud rotations, multiple projections, and voted key point matching. His basic idea is to rotate every 3D point cloud that represents a person on the x, y, or z-axis, iteratively project 3D points onto multiple 2.5D images in each step of the rotation. The marked key point is then extracted from the generated 2.5D image, and this smaller key point will replace the original face scan and its projection in the face database. In an extensive assessment using the GavabDB 3D facial recognition data set, their method has a recognition rate of 95% in neutral expressions, and 90% in recognition of faces such as smiles, laughing faces, and partial occlusion of faces.
Mayo and Zhang [106]은 포인트 클라우드 회전, 다중 투영 및 투표 된 키 포인트 매칭을 기반으로 3D 얼굴 인식 알고리즘을 제안하고 평가했습니다.
그의 기본 아이디어는 x, y 또는 z 축에서 사람을 나타내는 모든 3D 포인트 클라우드를 회전하고 회전의 각 단계에서 3D 포인트를 여러 2.5D 이미지에 반복적으로 투영하는 것입니다.
표시된 키 포인트는 생성 된 2.5D 이미지에서 추출되며이 작은 키 포인트는 원래 얼굴 스캔과 얼굴 데이터베이스의 투영을 대체합니다.
GavabDB 3D 얼굴 인식 데이터 세트를 사용한 광범위한 평가에서, 그들의 방법은 중립 표현에서 95 %, 미소, 웃는 얼굴, 얼굴 부분 가림과 같은 얼굴 인식에서 90 %의 인식률을 가지고 있습니다.
[106] Mayo M, Zhang E (2009) 3d face recognition using multiview key point matching. Advanced video and signal based surveillance. pp 290–295
Alyuz et al. [107] proposed a new type of a novel occlusion-resistant 3D face recognition system that can cope with severe occlusions of hair, hands, and glasses. A twostep registration model first detects the nose region on the curvedness-weighted convex shape index map and then uses the nose-based iterative closest point (ICP) algorithm to perform well alignment. The occlusion region is automatically determined by a generic facial model. After the occluded introduction of the non-facial part is removed, Gappy PCA is used to recover the entire face from the non-occlude facial surface. Experimental results obtained on realistically occluded facial images from the Bosphorus 3D face database show that using the score level fusion of the regional Linear Discriminant Analysis (LDA) classifier, this method improves the Rank-one recognition accuracy significantly from 76.12 to 94.23%.
Alyuz et al. [107]은 모발, 손, 안경의 심한 가림에 대처할 수있는 새로운 유형의 새로운 가림 방지 3D 얼굴 인식 시스템을 제안했습니다.
2 단계 등록 모델은 먼저 곡선 가중 볼록 모양 인덱스 맵에서 코 영역을 감지 한 다음 코 기반 반복 가장 가까운 지점 (ICP) 알고리즘을 사용하여 잘 정렬합니다.
교합 영역은 일반 얼굴 모델에 의해 자동으로 결정됩니다. 비 얼굴 부분의 폐쇄 된 도입이 제거 된 후, Gappy PCA는 폐쇄되지 않은 얼굴 표면에서 전체 얼굴을 복구하는 데 사용됩니다.
Bosphorus 3D 얼굴 데이터베이스에서 현실적으로 가려진 얼굴 이미지에서 얻은 실험 결과는 지역 선형 판별 분석 (LDA) 분류기의 점수 수준 융합을 사용하여 순위 1 인식 정확도를 76.12에서 94.23 %로 크게 향상 시켰음을 보여줍니다.
[107] Alyuz N, Gokberk LSRVLAB (2012) Robust 3d face recognition in the presence of realistic occlusions. Biometrics (ICB):111–118
Alyuz et al. [108] proposed a fully automatic and effective 3D face recognition method, which is robust to face occlusion. In order to align the occluded surfaces, they use a model based registration scheme in which the model is selected to adaptive the face’s occlusion. The alignment model is formed by the automatic inspection for validity and includes only the patch of the non occluded face. By registering the occlusion surfaces of the adaptive selection model, a one-to-one correspondence between the model and non-occlusion surface points is obtained. Therefore, occlusion face registration can be achieved. Compared with the registration strategy based on the overall face model (which is usually used for non-occluded surfaces), the recognition rate of the registration strategy is better than that of the overall face model and achieved about 20% improvement identification rate by the adaptive model method testing of Bosphorus and UMBDB databases. Drira et al. [58] proposed a new geometric framework for analyzing 3D faces and give a specific targets for comparison, matching, and averaging their shapes. They use radial curves from the tip of the nose to represent facial surfaces and use the elastic shape analysis of these curves to form a Riemannian frame to analyze the shape of the entire facial surface. The representation, together with the elastic Riemannian metric, seems to be naturally used to measure facial deformation and is very robust to partial obstructions and glasses, hair, etc.
Alyuz et al. [108]은 얼굴 가림에 강한 완전 자동적이고 효과적인 3D 얼굴 인식 방법을 제안했다.
폐색된 표면을 정렬하기 위해 모델 기반 등록 체계를 사용하여 모델을 선택하여 얼굴의 폐색을 조정합니다.
정렬 모델은 유효성에 대한 자동 검사에 의해 형성되며 가려지지 않은 얼굴의 패치만 포함합니다.
적응형 선택 모델의 폐색 표면을 등록하면 모델과 비 폐색 표면 점 사이의 일대일 대응이 얻어집니다.
따라서 폐색 얼굴 등록이 가능합니다.
전체 얼굴 모델 (일반적으로 비폐색 표면에 사용됨)을 기반으로 한 등록 전략과 비교할 때 등록 전략의 인식률은 전체 얼굴 모델보다 우수하며 적응 형 인식률을 약 20 % 개선했습니다.
Bosphorus 및 UMBDB 데이터베이스의 모델 방법 테스트. Drira et al. [58]은 3D 얼굴을 분석하고 모양을 비교, 일치 및 평균화하기위한 특정 목표를 제공하기위한 새로운 기하학적 프레임 워크를 제안했습니다.
코끝의 방사형 곡선을 사용하여 얼굴 표면을 표현하고 이러한 곡선의 탄성 모양 분석을 사용하여 전체 얼굴 표면의 모양을 분석하는 리만 프레임을 형성합니다.
탄성 Riemannian 메트릭과 함께 표현은 얼굴 변형을 측정하는 데 자연스럽게 사용되는 것으로 보이며 부분적인 장애물과 안경, 머리카락 등에 매우 강력합니다.
[108] Alyuz N, Gokberk B, Akarun L (2013) 3-d face recognition under occlusion using masked projection. Inform Forensics Secur 8:789–802
Open problems and perspectives 열린 문제와 관점
3D face recognition still have a lot of open problems for us to research, such as automatic facial expression recognition, age-invariant face recognition and transfer learning. As an important part of face recognition technology, facial expression (emotion) recognition (FER) has received extensive attention in the fields of human-computer interaction, security, robot manufacturing, automation, medical care, communication and driving in recent years, and become an active research field in the academic and industrial circles [109].
3D 얼굴 인식은 자동 얼굴 표정 인식, 연령 불변 얼굴 인식 및 전이 학습과 같이 우리가 연구해야 할 많은 문제를 여전히 가지고 있습니다.
얼굴 인식 기술의 중요한 부분 인 얼굴 표정 (감정) 인식 (FER)은 최근 인간-컴퓨터 상호 작용, 보안, 로봇 제조, 자동화, 의료, 통신 및 운전 분야에서 많은 관심을 받아 학계와 산업계의 활발한 연구 분야 [109].
3D facial expression recognition can overcome weakness and improve recognition accuracy. Some efforts have focused on the recognition of complex and spontaneous emotions rather than the identification of a typical emotional expression that is deliberately displayed [110–113].
3D 표정 인식은 약점을 극복하고 인식 정확도를 향상시킬 수 있습니다.
일부 노력은 의도적으로 표시되는 전형적인 감정 표현을 식별하는 것보다 복잡하고 자연스러운 감정을 인식하는 데 초점을 맞추 었습니다 [110-113].
[109] Hariri W, Tabia H, Farah N, Benouareth A, Declercq D (2017) 3d facial expression recognition using kernel methods on riemannian manifold. Eng Appl Artif Intell 64:25–32
[110] Zeng Z, Pantic GRTHM (2009) A survey of afect recognition methods: audio. Patt Analy Mach Intell 31:39–58
[111] Nicolaou M, Gunes MPH (2011) Continuous prediction of spontaneous afect from multiple cues and modalities in valencearousal space. Afect Comput 2:92–105
[112] Vinciarelli A, Pantic DHCPIPFDMSM (2012) Bridging the gap between social animal and unsocial machine: a survey of social signal processing. Forensics 3:69–87
[113] Kemelmacher-Shlizerman I, Basri R (2011) 3d face reconstruction from a single image using a single reference face shape. Pattern Anal Mach Intell 33:394–405
Most face recognition systems are sensitive to age variation. Although some of the earlier papers proposed some recognition methods under age-variations [114–117]. But there are still many problems that need us to explore. Transfer learning is a machine learning method where a model developed for a task is reused as the starting point for a model on a second task. The performance of 2D face recognition algorithms has significantly increased by leveraging the representational power of deep neural networks and the use of large-scale labeled training data. As opposed to 2D face recognition, training discriminative deep features for 3D face recognition is very difficult due to the lack of large-scale 3D face datasets. In [27], they show that transfer learning from a CNN trained on 2D face images can effectively work for 3D face recognition by finetuning the CNN with a relatively small number of 3D facial scans. 3D facial expression analysis, recognition under age-variations and transfer learning constitute three open problems that is still in its infancy. Future 3D technology will be applied to 3D sensing and 3D visualization. 3D sensing is a depth-sensing technology that augments camera capabilities for facial and object recognition in augmented reality, gaming, autonomous driving, and a wide range of applications. 3D sensing technology is about to go full-on mainstream as the likes of Apple, Google and Samsung race to incorporate 3D sensors into their next generation of smartphones. 3D visualization is the latest mainstream technology that allows designing objects in three-dimensional space with the help of 3D software and producing high-quality digital products. 3D visualization will be used in games, cartoons, films and motion comics because this is the exact sphere for developing and improvement the 3D visualization production.
대부분의 얼굴 인식 시스템은 연령 변화에 민감합니다.
초기 논문 중 일부는 연령대에 따라 몇 가지 인식 방법을 제안했지만 [114-117], 우리가 탐구해야 할 많은 문제가 여전히 있습니다.
전이 학습은 작업을 위해 개발된 모델을 두 번째 작업의 모델의 시작점으로 재사용하는 기계 학습 방법입니다.
2D 얼굴 인식 알고리즘의 성능은 심층 신경망의 표현력과 레이블이 지정된 대규모 훈련 데이터를 활용하여 크게 향상되었습니다.
2D 얼굴 인식과 달리 3D 얼굴 인식을 위한 차별적인 심층 기능을 훈련하는 것은 대규모 3D 얼굴 데이터 세트가 없기 때문에 매우 어렵습니다.
[27]에서는 2D 얼굴 이미지에 대해 학습된 CNN의 전이 학습이 비교적 적은 수의 3D 얼굴 스캔으로 CNN을 미세 조정하여 3D 얼굴 인식에 효과적으로 작동 할 수 있음을 보여줍니다.
3D 얼굴 표정 분석, 연령 변화에 따른 인식 및 전이 학습은 아직 초기 단계에있는 세 가지 열린 문제를 구성합니다.
향후 3D 기술은 3D 센싱 및 3D 시각화에 적용될 것입니다.
3D 감지는 증강 현실, 게임, 자율 주행 및 다양한 애플리케이션에서 얼굴 및 물체 인식을위한 카메라 기능을 강화하는 깊이 감지 기술입니다.
3D 감지 기술은 Apple, Google 및 Samsung과 같은 업체가 차세대 스마트 폰에 3D 센서를 통합하기 위해 경쟁함에 따라 본격적으로 주류가 될 것입니다. 3D 시각화는 3D 소프트웨어의 도움으로 3 차원 공간에서 물체를 설계하고 고품질 디지털 제품을 생산할 수있는 최신 주류 기술입니다.
3D 시각화는 3D 시각화 제작을 개발하고 개선하기위한 정확한 영역이기 때문에 게임, 만화, 영화 및 모션 만화에 사용됩니다.
[114] Park U, Tong AKJY (2010) Age invariant face recognition. Pattern Anal Mach Intell 32:947–954
[115] Lanitis A, Taylor CJ (2000) Robust face recognition using automaticage normalization. In: Mediterranean electrotechnical conference Vol.2, pp 478–481
[116] Lanitis A, Taylor TCC (2002) Toward automatic simulation of aging efects on face images. Pattern Anal Mach Intell 24:442–455
[117] Boussaad L, Benmohammed M, Benzid R (2016) Age invariant face recognition based on dct feature extraction and kernel fsher analysis. J Inform Process Syst 12(3):392–409
[27] Kim D, Hernandez JC M, Medioni, G (2017) Deep 3d face identifcation. arXiv:1703.10714 http://arxiv.org/ abs/1703.10714
Conclusions and discussion 결론 및 논의
3D face recognition is an important and popular area in recent years. More and more researchers are working on this field and presenting their 3D face recognition methods. In this paper, we surveyed some of the latest methods for 3D face recognition under expressions, occlusions, and pose variations. At first we summarized some various available 3D face databases. All of the above methods are tested on these databases. Almost all researchers use the following three formats of face data: point cloud, mesh and range data. All three type face data are obtained by 3D scanner.
3D 얼굴 인식은 최근 몇 년 동안 중요하고 인기있는 분야입니다.
점점 더 많은 연구자들이 이 분야에 대해 연구하고 있으며 3D 얼굴 인식 방법을 제시하고 있습니다.
이 논문에서는 표정, 가림, 포즈 변형에서 3D 얼굴 인식을위한 몇 가지 최신 방법을 조사했습니다.
처음에 우리는 사용 가능한 다양한 3D 얼굴 데이터베이스를 요약했습니다.
위의 모든 방법은 이러한 데이터베이스에서 테스트됩니다.
거의 모든 연구자들은 포인트 클라우드, 메시 및 범위 데이터의 세 가지 형식의 얼굴 데이터를 사용합니다.
세 가지 유형의 얼굴 데이터는 모두 3D 스캐너로 얻습니다.
The recognition methods are mainly divided into two categories: local methods and holistic methods. Although many experiments are carried out based on the holistic method, we believe that the local method is more suitable for 3D face recognition. Compared to holistic methods, the local method has stronger robustness in terms of occlusion and can obtain better experimental results. This survey divided 3D face recognition into three directions, pose-invariant 3D face recognition, expression-invariant 3D face recognition and occlusion-invariant 3D face recognition.
인식 방법은 주로 로컬 방법과 전체적인 방법의 두 가지 범주로 나뉩니다.
전체론적 방법을 기반으로 많은 실험이 수행되지만 3D 얼굴 인식에는 로컬 방법이 더 적합하다고 생각합니다.
전체론적 방법에 비해 국소적 방법은 폐색 측면에서 더 강건하며 더 나은 실험 결과를 얻을 수 있습니다.
이 설문 조사에서는 3D 얼굴 인식을 자세 불변 3D 얼굴 인식, 표정 불변 3D 얼굴 인식 및 가림 불변 3D 얼굴 인식의 세 가지 방향으로 구분했습니다.
This paper survey some methods for pose-invariant face recognition that handles a wide range of poses on publicly available databases. The recognition method is mainly local method. For instance, By using half face matching, a complete face model can be synthesized [55]. Using a statistical model in the radial curve’s shape space to overcome the data missing problem. There are two methods for Expression-Invariant 3d face recognition, one is local approaches based expression invariant approaches and the other is holistic approaches.
이 논문에서는 공개적으로 사용 가능한 데이터베이스에서 다양한 포즈를 처리하는 포즈 불변 얼굴 인식을위한 몇 가지 방법을 조사합니다.
인식 방법은 주로 로컬 방법입니다.
예를 들어 반 얼굴 매칭을 사용하여 완전한 얼굴 모델을 합성 할 수 있습니다 [55].
방사형 곡선의 모양 공간(radial curve’s shape space)에서 통계 모델을 사용하여 데이터 누락 문제를 극복합니다.
Expression-Invariant 3D 얼굴 인식에는 두 가지 방법이 있습니다.
하나는 로컬 방식 기반의 표현 고정 방식이고 다른 하나는 전체 론적 접근 방식입니다.
[55] Passalis G, Perakis P, Theoharis T, Kakadiaris IA (2011) Perakis: Using facial symmetry to handle pose variations in real-world 3d face recognition. Pattern Anal Mach Intell 33:1938–1951
This survey made a detailed introduction to the recognition of some researchers in the case of face occlusion in the following content, including the methods they used, the database they used and the recognition effect that was eventually achieved. Also, 3D face recognition technology has been applied in many fields, such as access control and automatic driving. The iPhone X uses Face ID, technology that unlocks the phone by using infrared and visible light scans to uniquely identify your face. It works in a variety of conditions and is extremely secure. In the world of autonomous driving, the autopilot needs to manage the hand-over between the automated and the manual modes. To have a smooth hand-over, it is important to make sure that the driver is alert and ready to take control of the car before the autopilot is disengaged. To have a smooth transition between modes of operation, Omron introduce 3D facial recognition technology that detects a drowsy or distracted driver. Considering the fact that one out of every six car accidents is attributed to a drowsy or distracted driver, the technology can have a huge impact even on the safety of manual driving Expression-invariant and occlusion-invariant 3D face recognition are very active and also proposed a lot of high recognition rates methods. We expect that all three directions can get a well performance in the near future.
이 설문 조사에서는 사용된 방법, 사용 된 데이터베이스 및 최종적으로 달성 된 인식 효과를 포함하여 다음 내용에서 일부 연구자들의 얼굴 가림에 대한 인식에 대해 자세히 소개했습니다.
또한 3D 얼굴 인식 기술은 출입 통제, 자동 운전 등 여러 분야에 적용되고 있습니다.
iPhone X는 적외선 및 가시 광선 스캔을 사용하여 얼굴을 고유하게 식별하여 휴대폰 잠금을 해제하는 기술인 Face ID를 사용합니다.
다양한 조건에서 작동하며 매우 안전합니다.
자율 주행의 세계에서 자동 조종 장치는 자동 모드와 수동 모드 간의 핸드 오버를 관리해야합니다.
원활한 핸드 오버를 위해서는 자동 조종 장치가 해제되기 전에 운전자가주의를 기울이고 차량을 제어 할 준비가되어 있는지 확인하는 것이 중요합니다.
작동 모드 사이를 원활하게 전환하기 위해 Omron은 졸리거나 산만한 운전자를 감지하는 3D 얼굴 인식 기술을 도입했습니다.
교통 사고 6 건 중 1 건이 졸리거나 산만한 운전자에 기인한다는 점을 감안하면 이 기술은 수동 운전의 안전성에도 큰 영향을 미칠 수 있다는 점을 감안할 때 표현 불변 및 가림 불변 3D 얼굴 인식이 매우 활발하며 제안되고있다.
많은 높은 인식률 방법. 우리는 세 방향 모두 가까운 장래에 좋은 성과를 거둘 수있을 것으로 기대합니다.
'지도학습 > 얼굴분석' 카테고리의 다른 글
| [ML]Haar Cascade classifier (0) | 2021.03.23 |
|---|---|
| PyramidBox : A Context-assisted Single Shot Face Detector. (0) | 2021.03.16 |
| Face recognition using Eigensurface on Kinect depth-maps,2016 (0) | 2021.03.15 |
| 3D Face Mesh Modeling from Range Images for 3D Face Recognition (0) | 2021.03.12 |
| Face Detection Ensemble with Methods Using Depth Information to Filter False Positives,2019 (0) | 2021.03.12 |



