PyramidBox: A Context-assisted Single Shot Face Detector.
PyramidBox : 상황에 맞는 단일 샷 얼굴 감지기.
Abstract.
Face detection has been well studied for many years and one of remaining challenges is to detect small, blurred and partially occluded faces in uncontrolled environment. This paper proposes a novel contextassisted single shot face detector, named PyramidBox to handle the hard face detection problem. Observing the importance of the context, we improve the utilization of contextual information in the following three aspects. First, we design a novel context anchor to supervise high-level contextual feature learning by a semi-supervised method, which we call it PyramidAnchors. Second, we propose the Low-level Feature Pyramid Network to combine adequate high-level context semantic feature and Low-level facial feature together, which also allows the PyramidBox to predict faces of all scales in a single shot. Third, we introduce a contextsensitive structure to increase the capacity of prediction network to improve the final accuracy of output. In addition, we use the method of Data-anchor-sampling to augment the training samples across different scales, which increases the diversity of training data for smaller faces. By exploiting the value of context, PyramidBox achieves superior performance among the state-of-the-art over the two common face detection benchmarks, FDDB and WIDER FACE. Our code is available in PaddlePaddle: https://github.com/PaddlePaddle/models/tree/develop/ fluid/face_detection. Keywords: face detection, context, single shot, PyramidBox
얼굴 인식은 수년 동안 잘 연구되어 왔으며 나머지 과제 중 하나는 통제되지 않은 환경에서 작고 흐릿하며 부분적으로 가려진 얼굴을 감지하는 것입니다. 이 논문은 딱딱한 얼굴 감지 문제를 처리하기 위해 PyramidBox라는 새로운 문맥 지원 싱글 샷 얼굴 감지기를 제안합니다.
컨텍스트의 중요성을 관찰하여 다음 세 가지 측면에서 컨텍스트 정보의 활용을 개선합니다.
먼저, 우리는 PyramidAnchors라고하는 준지도 방법을 통해 고수준의 문맥 특징 학습을 감독하는 새로운 컨텍스트 앵커를 설계합니다.
둘째, 적절한 고수준 컨텍스트 의미 특징과 저수준 얼굴 특징을 결합하여 PyramidBox가 한 번에 모든 스케일의 얼굴을 예측할 수 있도록하는 Low-level Feature Pyramid Network를 제안합니다.
셋째, 출력의 최종 정확도를 높이기 위해 예측 네트워크의 용량을 늘리기 위해 상황에 맞는 구조를 도입합니다.
또한 Data-anchor-sampling 방법을 사용하여 다양한 척도에서 훈련 샘플을 확대하여 작은 얼굴에 대한 훈련 데이터의 다양성을 높입니다.
컨텍스트의 가치를 활용함으로써 PyramidBox는 두 가지 일반적인 얼굴 감지 벤치 마크인 FDDB 및 WIDER FACE에 비해 최신 기술 중에서 우수한 성능을 달성합니다.
우리 코드는 PaddlePaddle : https://github.com/PaddlePaddle/models/tree/develop/ fluid / face_detection에서 사용할 수 있습니다.
키워드 : 얼굴 인식, 컨텍스트, 단일 샷, PyramidBox
1 Introduction
Face detection is a fundamental and essential task in various face applications. The breakthrough work by Viola-Jones [1] utilizes AdaBoost algorithm with Haar-Like features to train a cascade of face vs. non-face classifiers. Since that, numerous of subsequent works [2–7] are proposed for improving the cascade detectors. Then, [8–10] introduce deformable part models (DPM) into face detection tasks by modeling the relationship of deformable facial parts. These methods are mainly based on designed features which are less representable and trained by separated steps. With the great breakthrough of convolutional neural networks(CNN), a lot of progress for face detection has been made in recent years due to utilizing modern CNN-based object detectors, including R-CNN [11–14], SSD [15], YOLO [16], FocalLoss [17] and their extensions [56]. Benefiting from the powerful deep learning approach and end-to-end optimization, the CNN-based face detectors have achieved much better performance and provided a new baseline for later methods. Recent anchor-based detection frameworks aim at detecting hard faces in uncontrolled environment such as WIDER FACE [18]. SSH [19] and S3FD [20] develop scale-invariant networks to detect faces with different scales from different layers in a single network. Face R-FCN [21] re-weights embedding responses on score maps and eliminates the effect of non-uniformed contribution in each facial part using a position-sensitive average pooling. FAN [22] proposes an anchor-level attention by highlighting the features from the face region to detect the occluded faces. Though these works give an effective way to design anchors and related networks to detect faces with different scales, how to use the contextual information in face detection has not been paid enough attention, which should play a significant role in detection of hard faces. Actually, as shown in Fig. 1, it is clear that faces never occur isolated in the real world, usually with shoulders or bodies, providing a rich source of contextual associations to be exploited especially when the facial texture is not distinguishable for the sake of low-resolution, blur and occlusion. We address this issue by introducing a novel framework of context assisted network to make full use of contextual signals as the following steps.
얼굴 인식은 다양한 얼굴 애플리케이션에서 기본적이고 필수적인 작업입니다.
Viola-Jones [1]의 획기적인 작업은 Haar-Like 특징과 함께 AdaBoost 알고리즘을 사용하여 얼굴과 얼굴이 아닌 분류기의 캐스케이드를 훈련시킵니다. 그 이후로 많은 후속 작업 [2-7]이 캐스케이드 감지기를 개선하기 위해 제안되었습니다.
그런 다음 [8–10]은 변형 가능한 얼굴 부분의 관계를 모델링하여 변형 가능한 부분 모델 (DPM)을 얼굴 감지 작업에 도입합니다.
이러한 방법은 주로 표현하기 어렵고 분리된 단계로 훈련된 설계된 특징을 기반으로 합니다.
컨볼루션 신경망 (CNN)의 획기적인 발전과 함께 R-CNN [11–14], SSD [15]를 포함한 최신 CNN 기반 객체 감지기를 활용하여 최근 몇 년 동안 얼굴 감지에 대한 많은 진전이 이루어졌습니다.
YOLO [16], FocalLoss [17] 및 확장 [56]. 강력한 딥 러닝 접근 방식과 종단 간 최적화의 이점을 활용하여 CNN 기반 얼굴 감지기는 훨씬 더 나은 성능을 달성하고 이후 방법을 위한 새로운 기준을 제공했습니다.
최근 앵커 기반 탐지 프레임 워크는 WIDER FACE [18]와 같은 통제되지 않은 환경에서 단단한 얼굴을 탐지하는 것을 목표로합니다.
SSH [19]와 S3FD [20]는 단일 네트워크에서 서로 다른 계층의 서로 다른 스케일을 가진 얼굴을 감지하기 위해 스케일 불변 네트워크를 개발합니다.
Face R-FCN [21]은 score map에 임베딩 응답을 다시 가중치를 부여하고 위치 감지 평균 풀링을 사용하여 각 얼굴 부분에서 균일하지 않은 기여 효과를 제거합니다.
FAN [22]은 가려진 얼굴을 감지하기 위해 얼굴 영역의 특징을 강조하여 앵커 수준의 주의를 제안합니다.
이러한 작업은 다양한 스케일의 얼굴을 감지 할 수있는 앵커 및 관련 네트워크를 설계하는 효과적인 방법을 제공하지만 얼굴 감지에서 상황 정보를 사용하는 방법에 대해서는 충분히 주의를 기울이지 않아 딱딱한 얼굴 감지에 중요한 역할을해야합니다.
실제로, 그림 1에서 볼 수 있듯이 얼굴은 일반적으로 어깨나 몸으로 고립된 현실 세계에서 발생하지 않으며, 특히 저해상도, 흐림 및 폐색때문에 얼굴 질감을 구별 할 수 없는 경우에 활용 될 풍부한 맥락적 연관성 소스를 제공합니다.
다음 단계에 따라 상황별 신호를 최대한 활용하기 위해 상황 지원 네트워크의 새로운 프레임 워크를 도입하여이 문제를 해결합니다.

Firstly, the network should be able to learn features for not only faces, but also contextual parts such as heads and bodies. To achieve this goal, extra labels are needed and the anchors matched to these parts should be designed. In this work, we use a semi-supervised solution to generate approximate labels for contextual parts related to faces and a series of anchors called PyramidAnchors are invented to be easily added to general anchor-based architectures. Secondly, high-level contextual features should be adequately combined with the low-level ones. The appearances of hard and easy faces can be quite differ-ent, which implies that not all high-level semantic features are really helpful to smaller targets. We investigate the performance of Feature Pyramid Networks (FPN) [23] and modify it into a Low-level Feature Pyramid Network (LFPN) to join mutually helpful features together. Thirdly, the predict branch network should make full use of the joint feature. We introduce the Context-sensitive prediction module (CPM) to incorporate context information around the target face with a wider and deeper network. Meanwhile, we propose a max-in-out layer for the prediction module to further improve the capability of classification network. In addition, we propose a training strategy named as Data-anchor-sampling to make an adjustment on the distribution of the training dataset. In order to learn more representable features, the diversity of hard-set samples is important and can be gained by data augmentation across samples. For clarity, the main contributions of this work can be summarized as fivefold: 1. We propose an anchor-based context assisted method, called PyramidAnchors, to introduce supervised information on learning contextual features for small, blurred and partially occluded faces. 2. We design the Low-level Feature Pyramid Networks (LFPN) to merge contextual features and facial features better. Meanwhile, the proposed method can handle faces with different scales well in a single shot. 3. We introduce a context-sensitive prediction module, consisting of a mixed network structure and max-in-out layer to learn accurate location and classification from the merged features. 4. We propose the scale aware Data-anchor-sampling strategy to change the distribution of training samples to put emphasis on smaller faces. 5. We achieve superior performance over state-of-the-art on the common face detection benchmarks FDDB and WIDER FACE. The rest of the paper is organized as follows. Section 2 provides an overview of the related works. Section 3 introduces the proposed method. Section 4 presents the experiments and Section 5 concludes the paper.
첫째, 네트워크는 얼굴뿐만 아니라 머리와 몸과 같은 상황에 맞는 부분에 대한 특징을 학습 할 수 있어야 합니다.
이 목표를 달성하려면 추가 라벨이 필요하며 이러한 부품과 일치하는 앵커를 설계해야합니다.
이 작업에서는 반 감독 솔루션을 사용하여 얼굴과 관련된 컨텍스트 부분에 대한 대략적인 레이블을 생성하고 PyramidAnchors라는 일련의 앵커를 발명하여 일반 앵커 기반 아키텍처에 쉽게 추가 할 수 있습니다.
둘째, 높은 수준의 컨텍스트 기능은 낮은 수준의 기능과 적절하게 결합되어야합니다.
단단하고 쉬운 얼굴의 모양은 상당히 다를 수 있으며, 이는 모든 고수준 의미 체계가 작은 대상에 실제로 도움이되는 것은 아니라는 것을 의미합니다.
FPN (Feature Pyramid Networks) [23]의 성능을 조사하고, 이를 저수준 기능 피라미드 네트워크 (LFPN)로 수정하여 상호 도움이되는 기능을 함께 결합합니다.
셋째, 예측 분기 네트워크는 공동 기능을 최대한 활용해야합니다.
더 넓고 깊은 네트워크로 대상 얼굴 주변의 컨텍스트 정보를 통합하기 위해 컨텍스트 기반 예측 모듈 (CPM)을 도입합니다.
한편, 분류망의 성능을 더욱 향상시키기 위해 예측 모듈에 대한 max-in-out 계층을 제안한다.
또한 훈련 데이터 세트의 분포를 조정하기 위해 Data-anchor-sampling이라는 훈련 전략을 제안합니다. 더 많은 표현 가능한 기능을 배우려면 하드 세트 샘플의 다양성이 중요하며 샘플 전반에 걸친 데이터 증가를 통해 얻을 수 있습니다.
명확성을 위해 이 작업의 주요 기여는 5 가지로 요약 할 수 있습니다.
1. 우리는 작고 흐릿하고 부분적으로 가려진 얼굴에 대한 상황 별 특징 학습에 대한 감독 정보를 도입하기 위해 PyramidAnchors라고하는 앵커 기반 상황 지원 방법을 제안합니다.
2. 상황 별 특징과 얼굴 특징을 더 잘 병합하기 위해 LFPN (Low-level Feature Pyramid Networks)을 설계합니다. 한편, 제안된 방법은 한 번의 샷에서 다른 스케일의 얼굴을 잘 처리 할 수 있습니다.
3. 통합 된 기능에서 정확한 위치와 분류를 학습하기 위해 혼합 된 네트워크 구조와 max-in-out 계층으로 구성된 상황에 맞는 예측 모듈을 소개합니다.
4. 우리는 작은 얼굴에 중점을 두기 위해 훈련 샘플의 분포를 변경하기 위해 스케일 인식 데이터 앵커 샘플링 전략을 제안합니다.
5. 일반적인 얼굴 인식 벤치 마크인 FDDB 및 WIDER FACE에서 최신 기술보다 우수한 성능을 달성합니다.
나머지 논문은 다음과 같이 구성됩니다. 섹션 2는 관련 작업의 개요를 제공합니다. 3 장에서는 제안 된 방법을 소개한다. 4 장에서는 실험을, 5 장에서는 논문을 마무리합니다.
2 Related Work
Anchor-based Face Detectors. 앵커 기반 얼굴 감지기.
Anchor was first proposed by Faster R-CNN [14], and then it was widely used in both two-stage and one single shot object detectors. Then anchor-based object detectors [15,16] have achieved remarkable progress in recent years. Similar to FPN [23], Lin [17] uses translation-invariant anchor boxes, and Zhang [20] designs scales of anchors to ensure that the detector can handle various scales of faces well. FaceBoxes [24] introduces anchor densification to ensure different types of anchors have the same density on the image. S3FD [20] proposed anchor matching strategy to improve the recall rate of tiny faces.
Anchor는 Faster R-CNN [14]에 의해 처음 제안되었으며, 2단계 및 단일 단발 물체 감지기 모두에서 널리 사용되었습니다.
그런 다음 앵커 기반 물체 탐지기 [15,16]는 최근 몇 년 동안 놀라운 발전을 이루었습니다.
FPN [23]과 유사하게 Lin [17]은 변환 불변 앵커 박스를 사용하고 Zhang [20]은 검출기가 다양한 얼굴 스케일을 잘 처리 할 수 있도록 앵커 스케일을 설계합니다.
FaceBoxes [24]는 서로 다른 유형의 앵커가 이미지에서 동일한 밀도를 갖도록하기 위해 앵커 밀도를 도입했습니다.
S3FD [20]는 작은 얼굴의 회상률을 향상시키기 위해 앵커 매칭 전략을 제안했습니다.
Scale-invariant Face Detectors. 스케일 불변 얼굴 감지기
To improve the performance of face detector to handle faces of different scales, many state-of-the-art works [19, 20, 22,25] construct different structures in the same framework to detect faces with variant size, where the high-level features are designed to detect large faces while low-level features for small faces. In order to integrate high-level semantic feature into low-level layers with higher resolution, FPN [23] proposed a top-down architecture to use high-level semantic feature maps at all scales. Recently, FPN-style framework achieves great performance on both objection detection [17] and face detection [22].
다양한 스케일의 얼굴을 처리하는 얼굴 검출기의 성능을 개선하기 위해 많은 최신 작품 [19, 20, 22,25]이 동일한 프레임 워크에서 다양한 구조를 구성하여 다양한 크기의 얼굴을 검출합니다.
레벨 피처는 큰 얼굴을 감지하고 작은 얼굴을위한 로우 레벨 피처를 감지하도록 설계되었습니다.
높은 수준의 의미 론적 특징을 더 높은 해상도의 낮은 수준의 계층에 통합하기 위해 FPN [23]은 모든 규모에서 높은 수준의 의미론적 특징 맵을 사용하는 하향식 아키텍처를 제안했습니다.
최근에 FPN 스타일 프레임 워크는 이의 제기 감지 [17]와 얼굴 감지 [22] 모두에서 뛰어난 성능을 발휘합니다.
Context-associated Face Detectors. 상황에 따른 얼굴 감지
Recently, some works show the importance of contextual information for face detection, especially for finding small, blurred and occluded faces. CMS-RCNN [26] used Faster R-CNN in face detection with body contextual information. Hu et al. [27] trained separate detectors for different scales. SSH [19] modeled the context information by large filters on each prediction module. FAN [22] proposed an anchor-level attention, by highlighting the features from the face region, to detect the occluded faces.
최근 일부 작품은 얼굴 감지, 특히 작고 흐릿하고 가려진 얼굴을 찾는 데있어 상황 정보의 중요성을 보여줍니다.
CMS-RCNN [26]은 신체 상황 정보와 함께 얼굴 감지에 Faster R-CNN을 사용했습니다.
Hu et al. [27] 다른 스케일에 대해 훈련 된 별도의 검출기.
SSH [19]는 각 예측 모듈에서 큰 필터를 사용하여 컨텍스트 정보를 모델링했습니다.
FAN [22]은 가려진 얼굴을 감지하기 위해 얼굴 영역의 특징을 강조하여 앵커 수준의주의를 제안했습니다.
3 PyramidBox
This section introduces the context-assisted single shot face detector, PyramidBox. We first briefly introduce the network architecture in Sec. 3.1. Then we present a context-sensitive prediction module in Sec. 3.2, and propose a novel anchor method, named PyramidAnchors, in Sec. 3.3. Finally, Sec. 3.4 presents the associated training methodology including data-anchor-sampling and maxin-out.
이 섹션에서는 상황에 맞는 단일 샷 얼굴 감지기 인 PyramidBox를 소개합니다.
먼저 Sec에서 네트워크 아키텍처를 간략하게 소개합니다. 3.1. 그런 다음 Sec에서 상황에 맞는 예측 모듈을 제시합니다. 3.2, Sec.3.2에서 PyramidAnchors라는 새로운 앵커 방법을 제안합니다. 3.3. 마지막으로 Sec. 3.4는 데이터 앵커 샘플링 및 최대 출력을 포함한 관련 교육 방법론을 제공합니다.
3.1 Network Architecture

Anchor-based object detection frameworks with sophisticated design of anchors have been proved effective to handle faces of variable scales when predictions are made at different levels of feature map [14, 15, 19, 20, 22]. Meanwhile, FPN structures showed strength on merging high-level features with the lower ones. The architecture of PyramidBox(Fig. 2) uses the same extended VGG16 backbone and anchor scale design as S3FD [20], which can generate feature maps at different levels and anchors with equal-proportion interval. Low-level FPN is added on this backbone and a Context-sensitive Predict Module is used as a branch network from each pyramid detection layer to get the final output. The key is that we design a novel pyramid anchor method which generates a series of anchors for each face at different levels. The details of each component in the architecture are as follows:
정교한 앵커 설계를 사용하는 앵커 기반 객체 감지 프레임 워크는 다양한 수준의 특징 맵에서 예측이 이루어질 때 가변 스케일의 얼굴을 처리하는 데 효과적임이 입증되었습니다 [14, 15, 19, 20, 22].
한편 FPN 구조는 상위 기능과 하위 기능을 병합하는 데 강점을 보였습니다.
PyramidBox의 아키텍처 (그림 2)는 S3FD [20]와 동일한 확장 VGG16 백본 및 앵커 스케일 디자인을 사용합니다.
이는 동일한 비율 간격으로 서로 다른 레벨 및 앵커에서 피쳐 맵을 생성 할 수 있습니다.
이 백본에 저수준 FPN이 추가되고 상황에 맞는 예측 모듈이 각 피라미드 감지 계층에서 분기 네트워크로 사용되어 최종 출력을 얻습니다.
핵심은 서로 다른 수준에서 각면에 대해 일련의 앵커를 생성하는 새로운 피라미드 앵커 방법을 설계한다는 것입니다.
아키텍처의 각 구성 요소에 대한 세부 정보는 다음과 같습니다.
Scale-equitable Backbone Layers. 확장 가능한 백본 레이어.
We use the base convolution layers and extra convolutional layers in S3FD [20] as our backbone layers, which keep layers of VGG16 from conv 1 1 to pool 5, then convert fc 6 and fc 7 of VGG16 to conv fc layers, and then add more convolutional layers to make it deeper.
S3FD [20]의 기본 컨볼 루션 레이어와 추가 컨볼 루션 레이어를 백본 레이어로 사용합니다.
이 레이어는 VGG16 레이어를 conv 1 1에서 pool 5로 유지 한 다음 VGG16의 fc 6 및 fc 7을 conv fc 레이어로 변환 한 다음 추가합니다.
더 깊게 만들기 위해 더 많은 컨볼 루션 레이어.
Low-level Feature Pyramid Layers. 저수준 피처 피라미드 레이어.
To improve the performance of face detector to handle faces of different scales, the low-level feature with high resolution plays a key role. Hence, many state-of-the-art works [19, 20, 22, 25] construct different structures in the same framework to detect faces with variant size, where the high-level features are designed to detect large faces while low level features for small faces. In order to integrate high-level semantic feature into low-level layers with higher resolution, FPN [23] proposed a top-down architecture to use high-level semantic feature maps at all scales. Recently, FPN-style framework achieves great performance on both objection detection [17] and face detection [22].
다양한 스케일의 얼굴을 처리하는 얼굴 감지기의 성능을 개선하려면 고해상도의 저수준 기능이 중요한 역할을 합니다.
따라서 많은 최신 작품 [19, 20, 22, 25]은 동일한 프레임 워크에서 다양한 구조를 구성하여 다양한 크기의 얼굴을 감지합니다.
여기서 높은 수준의 특징은 큰 얼굴을 감지하고 낮은 수준의 특징은 감지하도록 설계되었습니다. 작은 얼굴 용. 높은 수준의 의미 론적 특징을 더 높은 해상도의 낮은 수준의 계층에 통합하기 위해 FPN [23]은 모든 규모에서 높은 수준의 의미론적 특징 맵을 사용하는 하향식 아키텍처를 제안했습니다.
최근에 FPN 스타일 프레임 워크는 이의 제기 감지 [17]와 얼굴 감지 [22] 모두에서 뛰어난 성능을 발휘합니다.
As we know, all of these works build FPN start from the top layer, which should be argued that not all high-level features are undoubtedly helpful to small faces. First, faces that are small, blurred and occluded have different texture feature from the large, clear and complete ones. So it is rude to directly use all high-level features to enhance the performance on small faces. Second, high-level features are extracted from regions with little face texture and may introduce noise information. For example, in the backbone layers of our Pyramid Box, the receptive field [20] of the top two layers conv 7 2 and conv 6 2 are 724 and 468, respectively. Notice that the input size of training image is 640, which means that the top two layers contain too much noisy context features, so they may not contribute to detecting medium and small faces.
아시다시피, 이러한 모든 작업은 FPN을 최상위 계층에서 시작하며, 이는 모든 고급 기능이 의심 할 여지없이 작은 얼굴에 도움이되는 것은 아니라는 점을 주장해야합니다.
첫째, 작고 흐릿하고 가려진 얼굴은 크고 깨끗하며 완전한 얼굴과 다른 질감 특징을 가지고 있습니다.
따라서 작은 얼굴의 성능을 향상시키기 위해 모든 고급 기능을 직접 사용하는 것은 무례합니다.
둘째, 얼굴 텍스처가 거의없는 영역에서 높은 수준의 특징을 추출하여 노이즈 정보를 도입 할 수 있습니다.
예를 들어 Pyramid Box의 백본 레이어에서 상위 2 개 레이어 conv 7 2 및 conv 6 2의 수용 필드 [20]는 각각 724 및 468입니다.
학습 이미지의 입력 크기는 640입니다.
즉, 상위 2 개 레이어에 노이즈가 많은 컨텍스트 특징이 너무 많이 포함되어있어 중간 및 작은 얼굴 감지에 기여하지 않을 수 있습니다.

Alternatively, we build the Low-level Feature Pyramid Network (LFPN) starting a top-down structure from a middle layer, whose receptive field should be close to the half of the input size, instead of the top layer. Also, the structure of each block of LFPN, as same as FPN [23], one can see Fig. 3(a) for details.
또는 수용 필드가 최상위 계층이 아닌 입력 크기의 절반에 가까워 야하는 중간 계층에서 하향식 구조를 시작하는 LFPN (Low-level Feature Pyramid Network)을 구축합니다. 또한 LFPN의 각 블록의 구조는 FPN [23]과 동일하게 그림 3 (a)를 참조 할 수있다.
Pyramid Detection Layers. 피라미드 감지 레이어.
We select lfpn 2, lfpn 1, lfpn 0, conv fc 7, conv 6 2 and conv 7 2 as detection layers with anchor size of 16, 32, 64, 128, 256 and 512, respectively. Here lfpn 2, lfpn 1 and lfpn 0 are output layer of LFPN based on conv 3 3, conv 4 3 and conv 5 3, respectively. Moreover, similar to other SSD-style methods, we use L2 normalization [28] to rescale the norm of LFPN layers.
lfpn 2, lfpn 1, lfpn 0, conv fc 7, conv 6 2 및 conv 72를 각각 앵커 크기가 16, 32, 64, 128, 256 및 512 인 감지 레이어로 선택합니다. 여기서 lfpn 2, lfpn 1 및 lfpn 0은 각각 conv 3 3, conv 4 3 및 conv 5 3을 기반으로하는 LFPN의 출력 레이어입니다. 또한 다른 SSD 스타일 방법과 마찬가지로 L2 정규화 [28]를 사용하여 LFPN 계층의 표준을 재조정합니다.
Predict Layers.

Each detection layer is followed by a Context-sensitive Predict Module (CPM), see Sec 3.2. Notice that the outputs of CPM are used for supervising pyramid anchors, see Sec. 3.3, which approximately cover face, head and body region in our experiments. The output size of the l-th CPM is wl × hl × cl , where wl = hl = 640/2 2+l is the corresponding feature size and the channel size cl equals to 20 for l = 0, 1, . . . , 5. Here the features of each channels are used for classification and regression of faces, heads and bodies, respectively, in which the classification of face need 4 (= cpl + cnl) channels, where cpl and cnl are max-in-out of foreground and background label respectively, satisfying Moreover, the classification of both head and body need two channels, while each of face, head and body have four channels to localize. Pyramid Box loss layers. For each target face, see in Sec. 3.3, we have a series of pyramid anchors to supervise the task of classification and regression simultaneously. We design a Pyramid Box Loss. see Sec. 3.4, in which we use softmax loss for classification and smooth L1 loss for regression.
각 감지 계층 뒤에는 상황에 맞는 예측 모듈 (CPM)이 있습니다 (3.2 절 참조). CPM의 출력은 피라미드 앵커를 감독하는 데 사용됩니다. 3.3, 우리 실험에서 얼굴, 머리 및 몸통 영역을 대략적으로 덮습니다. l 번째 CPM의 출력 크기는 wl × hl × cl입니다. 여기서 wl = hl = 640/2 2 + l은 해당 기능 크기이고 채널 크기 cl은 l = 0, 1,에 대해 20과 같습니다. . . , 5. 여기서 각 채널의 특징은 얼굴, 머리, 몸통의 분류 및 회귀에 각각 사용되며, 얼굴 분류에는 4 개 (= cpl + cnl) 채널이 필요하며, 여기서 cpl 및 cnl은 max-in-out입니다. 또한, 머리와 몸통의 분류는 2 개의 채널이 필요하고 얼굴, 머리, 몸통은 각각 4 개의 채널을 가지고 위치를 파악합니다. 피라미드 상자 손실 레이어. 각 대상 얼굴에 대해서는 Sec. 3.3, 분류 및 회귀 작업을 동시에 감독하는 일련의 피라미드 앵커가 있습니다. 우리는 Pyramid Box Loss를 설계합니다. Sec. 참조 3.4, 분류를 위해 소프트 맥스 손실을 사용하고 회귀를 위해 부드러운 L1 손실을 사용합니다.
3.2 Context-sensitive Predict Module 상황에 맞는 예측 모듈
Predict Module. 상황에 맞는 예측 모듈 예측 모듈.
In original anchor-based detectors, such as SSD [15] and YOLO [16], the objective functions are applied to the selected feature maps directly. As proposed in MS-CNN [29], enlarging the sub-network of each task can improve accuracy. Recently, SSH [19] increases the receptive field by placing a wider convolutional prediction module on top of layers with different strides, and DSSD [30] adds residual blocks for each prediction module. Indeed, both SSH and DSSD make the prediction module deeper and wider separately, so that the prediction module get the better feature to classify and localize. Inspired by the Inception-ResNet [31], it is quite clear that we can jointly enjoy the gain of wider and deeper network. We design the Context-sensitive Predict Module (CPM), see Fig. 3(b), in which we replace the convolution layers of context module in SSH by the residual-free prediction module of DSSD. This would allow our CPM to reap all the benefits of the DSSD module approach while remaining rich contextual information from SSH context module.
SSD [15] 및 YOLO [16]와 같은 원래 앵커 기반 탐지기에서 목적 함수는 선택한 기능 맵에 직접 적용됩니다. MS-CNN [29]에서 제안한 것처럼 각 작업의 서브 네트워크를 확대하면 정확도를 높일 수 있습니다. 최근 SSH [19]는 보폭이 다른 레이어 위에 더 넓은 컨볼 루션 예측 모듈을 배치하여 수용 필드를 증가시키고 DSSD [30]는 각 예측 모듈에 대한 잔차 블록을 추가합니다. 실제로 SSH와 DSSD는 모두 예측 모듈을 더 깊고 넓게 개별적으로 만들어 예측 모듈이 더 나은 분류 및 지역화 기능을 갖도록합니다. Inception-ResNet [31]에서 영감을 받아 더 넓고 깊은 네트워크의 이득을 함께 누릴 수 있다는 것은 분명합니다. 우리는 그림 3 (b)를 참조하여 Context-sensitive Predict Module (CPM)을 설계합니다. 여기서 SSH에서 컨텍스트 모듈의 컨볼 루션 레이어를 DSSD의 잔차없는 예측 모듈로 대체합니다. 이를 통해 CPM은 SSH 컨텍스트 모듈에서 풍부한 컨텍스트 정보를 유지하면서 DSSD 모듈 접근 방식의 모든 이점을 얻을 수 있습니다.
Max-in-out.
The conception of Maxout was first proposed by Goodfellow et al. [32]. Recently, S3FD [20] applied max-out background label to reduce the false positive rate of small negatives. In this work, we use this strategy on both positive and negative samples. Denote it as max-in-out, see Fig. 3(c). We first predict cp + cn scores for each prediction module, and then select max cp as the positive score. Similarly, we choose the max score of cn to be the negative score. In our experiment, we set cp = 1 and cn = 3 for the first prediction module since that small anchors have more complicated background [24], while cp = 3 and cn = 1 for other prediction modules to recall more faces.
Maxout의 개념은 Goodfellow 등이 처음 제안했습니다. [32]. 최근 S3FD [20]는 작은 음성의 위양성 비율을 줄이기 위해 max-out 배경 라벨을 적용했습니다. 이 작업에서는 양성 및 음성 샘플 모두에이 전략을 사용합니다. max-in-out으로 표시합니다. 그림 3 (c)를 참조하십시오. 먼저 각 예측 모듈에 대한 cp + cn 점수를 예측 한 다음 양수 점수로 max cp를 선택합니다. 마찬가지로 cn의 최대 점수를 음수 점수로 선택합니다. 우리의 실험에서는 작은 앵커가 더 복잡한 배경을 가지고 있기 때문에 첫 번째 예측 모듈에 대해 cp = 1 및 cn = 3을 설정하고 [24], 다른 예측 모듈에 대해 더 많은 얼굴을 회상하기 위해 cp = 3 및 cn = 1을 설정했습니다.
3.3 Pyramid Anchors
Recently anchor-based object detectors [15–17, 23] and face detectors [20, 24] have achieved remarkable progress. It has been proved that balanced anchors for each scale are necessary to detect small faces [20]. But it still ignored the context feature at each scale because the anchors are all designed for face regions. To address this problem, we propose a novel alternatively anchor method, named Pyramid Anchors.
최근 앵커 기반 물체 탐지기 [15–17, 23] 및 얼굴 탐지기 [20, 24]는 놀라운 발전을 이루었습니다. 작은 얼굴을 감지하려면 각 스케일에 대해 균형 잡힌 앵커가 필요하다는 것이 입증되었습니다 [20]. 그러나 앵커는 모두 얼굴 영역 용으로 설계 되었기 때문에 각 스케일에서 컨텍스트 기능을 무시했습니다. 이 문제를 해결하기 위해 Pyramid Anchors라는 새로운 대안 앵커 방법을 제안합니다.
For each target face, Pyramid Anchors generate a series of anchors corresponding to larger regions related to a face that contains more contextual information, such as head, shoulder and body. We choose the layers to set such anchors by matching the region size to the anchor size, which will supervise higher-level layers to learn more representable features for lower-level scale faces. Given extra labels of head, shoulder or body, we can accurately match the anchors to ground truth to generate the loss. As it’s unfair to add additional labels, we implement it in a semi-supervised way under the assumption that regions with the same ratio and offset to different faces own similar contextual feature.
각 대상 얼굴에 대해 Pyramid Anchors는 머리, 어깨 및 몸통과 같은 더 많은 컨텍스트 정보를 포함하는 얼굴과 관련된 더 큰 영역에 해당하는 일련의 앵커를 생성합니다. 영역 크기를 앵커 크기와 일치시켜 이러한 앵커를 설정하는 레이어를 선택합니다. 그러면 더 높은 수준의 레이어를 감독하여 더 낮은 수준의 배율면에 대해 더 많은 표현 가능한 기능을 학습합니다. 머리, 어깨 또는 몸의 추가 레이블이 주어지면 앵커를 접지 진실에 정확하게 일치시켜 손실을 생성 할 수 있습니다. 추가 라벨을 추가하는 것은 불공평하기 때문에 비율이 같고 다른 얼굴에 오프셋이있는 영역이 유사한 문맥 특징을 소유한다는 가정하에 반 감독 방식으로 구현합니다.
Namely, we can use a set of uniform boxes to approximate the actual regions of head, shoulder and body, as long as features from these boxes are similar among different faces. For a target face localized at regiontarget at original image, considering the anchori,j , which means the j-th anchor at the i-th feature layer with stride size si , we define the label of k-th pyramid-anchor by for k = 0, 1, . . . , K, respectively, where spa is the stride of pyramid anchors. anchori,j ·si denotes the corresponding region in the original image of anchori,j , and anchori,j · si/spa k represents the corresponding down-sampled region by stride spa k . The threshold is the same as other anchor-based detectors. Besides, a PyramidBox Loss will be demonstrated in Sec. 3.4.
즉,이 상자의 피처가 서로 다른면에서 유사한 한 균일 한 상자 세트를 사용하여 머리, 어깨 및 몸의 실제 영역을 근사 할 수 있습니다. 원본 이미지의 regiontarget에 국한된 대상 얼굴의 경우, 보폭 크기가 si 인 i 번째 피처 레이어의 j 번째 앵커를 의미하는 anchori, j를 고려하여 k에 대해 k 번째 피라미드 앵커의 레이블을 정의합니다. = 0, 1,. . . , K, 여기서 스파는 피라미드 앵커의 보폭입니다. anchori, j · si는 anchori, j의 원본 이미지에서 해당 영역을 나타내고 anchori, j · si / spa k는 stride spa k에 의해 해당하는 다운 샘플링 된 영역을 나타냅니다. 임계 값은 다른 앵커 기반 탐지기와 동일합니다. 또한 PyramidBox Loss는 Sec. 3.4.
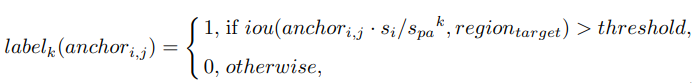

In our experiments, we set the hyper parameter spa = 2 since the stride of adjacent prediction modules is 2. Furthermore, let threshold = 0.35 and K = 2. Then label0, label1 and label2 are labels of face, head and body respectively. One can see that a face would generate 3 targets in three continuous prediction modules, which represent for the face itself, the head and body corresponding to the face. Fig. 4 shows an example.
우리의 실험에서는 인접한 예측 모듈의 보폭이 2이므로 하이퍼 매개 변수 spa = 2를 설정했습니다. 또한 임계 값 = 0.35 및 K = 2로 설정합니다. 그러면 label0, label1 및 label2는 각각 얼굴, 머리 및 몸의 레이블입니다. 얼굴 자체, 얼굴에 해당하는 머리와 몸통을 나타내는 3 개의 연속 예측 모듈에서 얼굴이 3 개의 타겟을 생성한다는 것을 알 수 있습니다. 그림 4는 예를 보여줍니다.
Benefited from the Pyramid Box, our face detector can handle small, blurred and partially occluded faces better. Notice that the pyramid anchors are generated automatically without any extra label and this semi-supervised learning help Pyramid Anchors extract approximate contextual features. In prediction process, we only use output of the face branch, so no additional computational cost is incurred at runtime, compared to standard anchor-based face detectors.
Pyramid Box의 이점을 활용하여 우리의 얼굴 감지기는 작고 흐릿하고 부분적으로 가려진 얼굴을 더 잘 처리 할 수 있습니다. 피라미드 앵커는 추가 레이블없이 자동으로 생성되며이 반지도 학습은 피라미드 앵커가 대략적인 컨텍스트 특징을 추출하는 데 도움이됩니다. 예측 프로세스에서는 얼굴 분기의 출력 만 사용하므로 표준 앵커 기반 얼굴 감지기에 비해 런타임에 추가 계산 비용이 발생하지 않습니다.
3.4 Training
In this section, we introduce the training dataset, data augmentation, loss function and other implementation details.
이 섹션에서는 훈련 데이터 세트, 데이터 증가, 손실 함수 및 기타 구현 세부 정보를 소개합니다.
Train dataset.
We trained Pyramid Box on 12, 880 images of the WIDER FACE training set with color distort, random crop and horizontal flip.
우리는 색상 왜곡, 무작위 자르기 및 수평 뒤집기가 포함 된 WIDER FACE 교육 세트의 12,880 개 이미지에 대해 Pyramid Box를 교육했습니다.
Data-anchor-sampling. 데이터 앵커 샘플링.
Data sampling [33] is a classical subject in statistics, machine learning and pattern recognition, it achieves great development in recent years. For the task of objection detection, Focus Loss [17] address the class imbalance by reshaping the standard cross entropy loss. Here we utilize a data augment sample method named Data-anchor-sampling. In short, data-anchor-sampling resizes train images by reshaping a random face in this image to a random smaller anchor size. More specifically, we first randomly select a face of size sface in a sample.
데이터 샘플링 [33]은 통계, 기계 학습 및 패턴 인식의 고전적인 주제이며 최근 몇 년간 큰 발전을 이루었습니다. 반대 감지 작업의 경우 Focus Loss [17]는 표준 교차 엔트로피 손실을 재구성하여 클래스 불균형을 해결합니다. 여기서는 Data-anchor-sampling이라는 데이터 증가 샘플 방법을 사용합니다. 요컨대, data-anchor-sampling은이 이미지의 임의의 얼굴을 임의의 작은 앵커 크기로 재구성하여 기차 이미지의 크기를 조정합니다. 더 구체적으로, 먼저 샘플에서 크기면의 얼굴을 무작위로 선택합니다.

As previously mentioned that the scales of anchors in our PyramidBox, as shown in Sec. 3.1, are $s_i=2^{4+i}$ , for i = 0, 1, . . . , 5, let $i_{anchor}= argmin_iabs(s_{anchor}_i − s_{face}) be the index of the nearest anchor scale from the selected face, then we choose a random index itarget in the set {0, 1, . . . , min(5, $i_{anchor}$ + 1)}
finally, we resize the face of size of sface to the size of $s_{target}=random(s_i_{target}/2, s_i_{target}∗2)$. Thus, we got the image resize scale $s^∗=s_{target}/s_{face}$.
By resizing the original image with the scale s ∗ and cropping a standard size of 640 × 640 containing the selected face randomly, we get the anchor-sampled train data. For example, we first select a face randomly, suppose its size is 140, then its nearest anchor-size is 128, then we need to choose a target size from 16, 32, 64, 128 and 256. In general, assume that we select 32, then we resize the original image by scale of 32/140 = 0.2285. Finally, by cropping a 640 × 640 sub-image from the last resized image containing the originally selected face, we get the sampled train data. As shown in Fig. 5, data-anchor-sampling changes the distribution of the train data as follows: 1) the proportion of small faces is larger than the large ones. 2) generate smaller face samples through larger ones to increase the diversity of face samples of smaller scales.
앞서 언급했듯이 PyramidBox의 앵커 스케일은 Sec. 3.1, i = 0, 1, 인 경우 si = 24 + i입니다. . . , 5, ianchor = argminiabs (sanchori − sface)를 선택한면에서 가장 가까운 앵커 스케일의 인덱스로 설정 한 다음 세트 {0, 1,에서 임의 인덱스 itarget을 선택합니다. . . , min (5, ianchor + 1)} 마지막으로, 표면 크기의면을 starget = random (sitarget / 2, sitarget ∗ 2) 크기로 조정합니다. 따라서 이미지 크기 조정 스케일 s ∗ = starget / sface를 얻었습니다. 스케일 s *로 원본 이미지의 크기를 조정하고 선택한 얼굴을 포함하는 표준 크기 640 × 640을 무작위로 잘라내어 앵커 샘플링 된 기차 데이터를 얻습니다. 예를 들어, 먼저 얼굴을 무작위로 선택하고 크기가 140이고 가장 가까운 앵커 크기가 128이라고 가정하고 16, 32, 64, 128 및 256 중에서 대상 크기를 선택해야합니다. 일반적으로 다음과 같이 가정합니다. 32를 선택한 다음 32/140 = 0.2285 배율로 원본 이미지의 크기를 조정합니다. 마지막으로, 원래 선택된 얼굴을 포함하는 마지막 크기 조정 된 이미지에서 640 × 640 하위 이미지를 잘라내어 샘플링 된 기차 데이터를 얻습니다. 그림 5에서 볼 수 있듯이 데이터 앵커 샘플링은 기차 데이터의 분포를 다음과 같이 변경합니다.
1) 작은면의 비율이 큰 면보다 큽니다.
2) 더 작은 얼굴 샘플을 통해 더 작은 얼굴 샘플을 생성하여 작은 스케일의 얼굴 샘플의 다양성을 높입니다.
PyramidBox loss.
As a generalization of the multi-box loss in [13], we employ the PyramidBox Loss function for an image is defined as L({pk,i}, {tk,i}) = X k λkLk({pk,i}, {tk,i}), (2) where the k-th pyramid-anchor loss is given by Lk({pk,i}, {tk,i}) = λ Nk,cls X ik Lk,cls(pk,i, p∗ k,i) + 1 Nk,reg X ik p ∗ k,iLk,reg(tk,i, t∗ k,i). (3) Here k is the index of pyramid-anchors (k = 0, 1, and 2 represents for face, head and body, respectively, in our experiments), and i is the index of an anchor and pk,i is the predicted probability of anchor i being the k-th object (face, head or body). The ground-truth label defined by p ∗ k,i = ( 1, if the anchor down-sampled by stride spa k is positive, 0, otherwise. (4) For example, when k = 0, the ground-truth label is equal to the label in Fast RCNN [13], otherwise, when k ≥ 1, one can determine the corresponding label by matching between the down-sampled anchors and ground-truth faces. Moreover, tk,i is a vector representing the 4 parameterized coordinates of the predicted bounding box, and t ∗ k,i is that of ground-truth box associated with a positive anchor, we can define it by t ∗ k,i = ( t ∗ x + 1−s k pa 2 t ∗ wsw,k + ∆x,k, t∗ y + 1−s k pa 2 t ∗ h sh,k + ∆y,k, s k pa t ∗ wsw,k − 2∆x,k, sk pa t ∗ h sh,k − 2∆y,k),
where ∆x,k and ∆y,k denote offset of shifts, sw,k and sh,k are scale factors respect to width and height respectively. In our experiments, we set ∆x,k = ∆y,k = 0, sw,k = sh,k = 1 for k < 2 and ∆x,2 = 0, ∆y,2 = t ∗ h , sw,2 = 7 8 , sh,2 = 1 for k = 2. The classification loss Lk,cls is log loss over two classes ( face vs. not face) and the regression loss Lk,reg is the smooth L1 loss defined in [13]. The term p ∗ k,iLk,reg means the regression loss is activated only for positive anchors and disabled otherwise. The two terms are normalized with Nk,cls, Nk,reg, and balancing weights λ and λk for k = 0, 1, 2.
[13]에서 멀티 박스 손실의 일반화로 이미지에 대해 PyramidBox Loss 함수를 사용하여
$L({p_{k, i}}, {t_{k, i}})=\sum_kλ_kL_k({p_{k, i}},{t_{k, i}})$ (2)
여기서 k 번째 피라미드 앵커 손실은
$L_k({p_{k, i}},{t_{k, i}})=\fraction{λ}{N_{k, cls}}\sum_i_kL_{k, cls}(p_{k, i},p^∗_{k, i})+\fraction{1}{N_{k, reg}}\sum_i_kp^∗_{k, i}L_{k, reg}(t_{k, i}, t^∗_{k, i})$(3)
여기서 k는 피라미드 앵커의 인덱스 (k = 0, 1, 2는 우리 실험에서 각각 얼굴, 머리, 몸을 나타냄)이고, i는 앵커의 인덱스이고 pk, i는 앵커 i가 k 번째 객체 (얼굴, 머리 또는 몸)가 될 확률을 예측했습니다. p ∗ k, i = (1, stride spa k에 의해 다운 샘플링 된 앵커가 양수이면 0, 그렇지 않으면 0으로 정의됩니다.

예를 들어 k = 0 일 때 ground-truth 레이블은 다음과 같습니다. Fast RCNN [13]의 라벨과 같고, 그렇지 않으면 k ≥ 1 인 경우 다운 샘플링 된 앵커와 실 측면을 일치시켜 해당 라벨을 결정할 수 있습니다. 또한 tk, i는 매개 변수화 된 4를 나타내는 벡터입니다. 예측 된 경계 상자의 좌표, t ∗ k, i는 포지티브 앵커와 관련된 ground-truth box의 좌표입니다. 우리는 (5) 정의 할 수 있습니다.

여기서 ∆x, k 및 ∆y, k는 시프트 오프셋을 나타내며, $s_{w, k}$ 및 $s_{h, k}$는 각각 너비와 높이에 대한 축척 계수입니다. 실험에서 k <2 및 $∆_{x,2}=0, ∆_{y, 2}=t^∗_h,s_{w,2}$에 대해 $∆_{x,k}=∆_{y,k}=0,s_{w,k}=s_{h,k}=1$로 설정했습니다. $2=\fraction{7}{8},s_{h,2}=1$ for k = 2 분류 손실 $L_{k, cls}$는 두 클래스 (얼굴 대 얼굴 아님)에 대한 로그 손실이고 회귀 손실 $L_{k, reg}$는 [13에서 정의 된 부드러운 L1 손실입니다. ]. 용어 $p^∗_{k,i}L_{k, reg}$는 회귀 손실이 양의 앵커에 대해서만 활성화되고 그렇지 않으면 비활성화됨을 의미합니다. 두 항은 Nk, cls, Nk, reg 및 k = 0, 1, 2에 대해 균형 가중치 λ 및 λk로 정규화됩니다.
Optimization.
As for the parameter initialization, our PyramidBox use the pre-trained parameters from VGG16 [34]. The parameters of conv fc 67 and conv fc 7 are initialized by sub-sampling parameters from fc 6 and fc 7 of VGG16 and the other additional layers are randomly initialized with “xavier” in [35]. We use a learning rate of 10−3 for 80k iterations, and 10−4 for the next 20k iterations, and 10−5 for the last 20k iterations on the WIDER FACE training set with batch size 16. We also use a momentum of 0.9 and a weight decay of 0.0005 [36].
매개 변수 초기화와 관련하여 PyramidBox는 VGG16 [34]의 사전 훈련 된 매개 변수를 사용합니다. conv fc 67 및 conv fc 7의 매개 변수는 VGG16의 fc 6 및 fc 7의 서브 샘플링 매개 변수에 의해 초기화되고 다른 추가 레이어는 [35]에서 "xavier"로 무작위로 초기화됩니다. 우리는 배치 크기가 16 인 WIDER FACE 훈련 세트에서 80k 반복에 대해 10-3, 다음 20k 반복에 10-4, 마지막 20k 반복에 10-5의 학습률을 사용합니다. 또한 모멘텀 0.9를 사용합니다. 0.0005의 무게 감소 [36].
4 Experiments
In this section, we firstly analyze the effectiveness of our PyramidBox through a set of experiments, and then evaluate the final model on WIDER FACE and FDDB face detection benchmarks.
이 섹션에서는 먼저 일련의 실험을 통해 PyramidBox의 효과를 분석 한 다음 WIDER FACE 및 FDDB 얼굴 감지 벤치 마크에서 최종 모델을 평가합니다.
4.1 Model Analysis
We analyze our model on the WIDER FACE validation set by contrast experiments.
대조 실험에 의해 설정된 WIDER FACE 유효성 검사에서 모델을 분석합니다.
Baseline.
Our PyramidBox shares the same architecture of S3FD, so we directly use it as a baseline.
PyramidBox는 S3FD와 동일한 아키텍처를 공유하므로 이를 기준으로 직접 사용합니다.
Contrast Study. 대조 연구.
To better understand Pyramid Box, we conduct contrast experiments to evaluate the contributions of each proposed component, from which we can get the following conclusions.
Pyramid Box를 더 잘 이해하기 위해 각 제안 된 구성 요소의 기여도를 평가하는 대조 실험을 수행하여 다음과 같은 결론을 얻을 수 있습니다.
Low-level feature pyramid network (LFPN) is crucial for detecting hard faces.
저수준 피처 피라미드 네트워크 (LFPN)는 딱딱한 얼굴을 감지하는 데 중요합니다.

The results listed in Table 1 prove that LFPN started from a middle layer, using conv fc7 in our Pyramid Box, is more powerful, which implies that features with large gap in scale may not help each other. The comparison between the first and forth column of Table 1 indicates that LFPN increases the mAP by 1.9% on hard subset. This significant improvement demonstrates the effectiveness of joining high-level semantic features with the low-level ones.
표 1에 나열된 결과는 Pyramid Box에서 conv fc7을 사용하여 중간 계층에서 시작된 LFPN이 더 강력하다는 것을 증명하며, 이는 규모가 큰 기능이 서로 도움이되지 않을 수 있음을 의미합니다. 표 1의 첫 번째 열과 네 번째 열 사이의 비교는 LFPN이 하드 서브 세트에서 mAP를 1.9 % 증가 시킨다는 것을 나타냅니다. 이 중요한 개선 사항은 높은 수준의 의미 체계와 낮은 수준의 의미 체계를 결합하는 효과를 보여줍니다.
Data-anchor-sampling makes detector easier to train.
데이터 앵커 샘플링을 사용하면 감지기를 더 쉽게 학습시킬 수 있습니다.
We employ Data-anchor-sampling based on LFPN network and the result shows that our data-anchor-sampling effectively improves the performance. The mAP is increased by 0.4%, 0.4% and 0.6% on easy, medium and hard subset, respectively. One can see that Data-anchor-sampling works well not only for small hard faces, but also for easy and medium faces.
우리는 LFPN 네트워크를 기반으로 데이터 앵커 샘플링을 사용하고 그 결과 데이터 앵커 샘플링이 성능을 효과적으로 향상시키는 것으로 나타났습니다. mAP는 easy, medium 및 hard 하위 집합에서 각각 0.4 %, 0.4 % 및 0.6 % 증가합니다. 데이터 앵커 샘플링은 작고 단단한 얼굴뿐만 아니라 쉽고 중간 얼굴에서도 잘 작동한다는 것을 알 수 있습니다.
Pyramid Anchor and Pyramid Box loss is promising. Pyramid Anchor 및 Pyramid Box 손실은 유망합니다.

By comparing the first and last column in Table 2, one can see that Pyamid Anchor effectively improves the performance, i.e., 0.7%, 0.6% and 0.9% on easy, medium and hard, respectively. This dramatical improvement shows that learning contextual information is helpful to the task of detection, especially for hard faces.
표 2의 첫 번째 열과 마지막 열을 비교하면 Pyamid Anchor가 각각 easy, medium 및 hard에서 각각 0.7 %, 0.6 % 및 0.9 %의 성능을 효과적으로 개선한다는 것을 알 수 있습니다. 이 극적인 개선은 상황 별 정보를 학습하는 것이 특히 딱딱한 얼굴의 감지 작업에 도움이된다는 것을 보여줍니다.
Wider and deeper context prediction module is better.
더 넓고 깊은 컨텍스트 예측 모듈이 더 좋습니다.


Table 3 shows that the performance of CPM is better than both DSSD module and SSH context module. Notice that the combination of SSH and DSSD gains very little compared to SSH alone, which indicates that large receptive field is more important to predict the accurate location and classification. In addition, by comparing the last two column of Table 4, one can find that the method of Max-in-out improves the mAP on WIDER FACE validation set about +0.2%(Easy), +0.3%(Medium) and +0.1%(Hard), respectively To conclude this section, we summarize our results in Table 4, from which one can see that mAP increase 2.1%, 2.3% and 4.7% on easy, medium and hard subset, respectively. This sharp increase demonstrates the effectiveness of proposed Pyramid Box, especially for hard faces.
표 3은 CPM의 성능이 DSSD 모듈과 SSH 컨텍스트 모듈 모두보다 우수하다는 것을 보여줍니다. SSH와 DSSD의 조합은 SSH 단독에 비해 거의 이득이 없습니다. 이는 정확한 위치와 분류를 예측하는 데 큰 수용 필드가 더 중요하다는 것을 나타냅니다. 또한 표 4의 마지막 두 열을 비교해 보면 Max-in-out 방법이 WIDER FACE 검증 세트에서 mAP를 약 + 0.2 % (Easy), + 0.3 % (Medium) 및 +0.1로 향상시키는 것을 확인할 수 있습니다. % (Hard), 각각이 섹션을 마무리하기 위해 표 4에 결과를 요약하여 mAP가 easy, medium 및 hard 하위 집합에서 각각 2.1 %, 2.3 % 및 4.7 % 증가하는 것을 볼 수 있습니다. 이 급격한 증가는 특히 단단한 얼굴에 대해 제안 된 피라미드 상자의 효과를 보여줍니다.
4.2 Evaluation on Benchmark 벤치 마크 평가
We evaluate our Pyramid Box on the most popular face detection benchmarks, including Face Detection Data Set and Benchmark (FDDB) [37] and WIDER FACE [38].
우리는 얼굴 인식 데이터 세트 및 벤치 마크 (FDDB) [37] 및 WIDER FACE [38]를 포함하여 가장 인기있는 얼굴 인식 벤치 마크에서 피라미드 상자를 평가합니다.
FDDB Dataset.

It has 5, 171 faces in 2, 845 images collected from the Yahoo! news website. We evaluate our face detector on FDDB against the other state-of-art methods [4, 18, 20, 24, 29, 39–53]. The Pyramid Box achieves state-of-art performance and the result is shown in Fig. 6(a) and Fig. 6(b).
Yahoo!에서 수집 한 2,845 개의 이미지에 5,171 개의 얼굴이 있습니다. 뉴스 웹 사이트. FDDB의 얼굴 감지기를 다른 최첨단 방법과 비교하여 평가합니다 [4, 18, 20, 24, 29, 39–53]. Pyramid Box는 최첨단 성능을 제공하며 그 결과는 그림 6 (a)와 그림 6 (b)에 나와 있습니다.
WIDER FACE Dataset.

It contains 32, 203 images and 393, 703 annotated faces with a high degree of variability in scale, pose and occlusion. The database is split into training (40%), validation (10%) and testing (50%) set, where both validation and test set are divided into “easy”, “medium” and “hard” subsets, regarding the difficulties of the detection. Our Pyramid Box is trained only on the training set and evaluated on both validation set and testing set comparing with the state-of-the-art face detectors, such as [6,19–22,24–27,29,38,39,42,50,54,55]. Fig. 7 presents the precision-recall curves and mAP values. Our Pyramid Box outperforms others 0.889 (hard) for validation set, and 0.956 (easy), 0.946 (medium), 0.887 (hard) for testing set.
32, 203 개의 이미지와 393, 703 개의 주석이 달린 얼굴이 포함되어 있으며 스케일, 포즈 및 오 클루 전이 매우 다양합니다. 데이터베이스는 훈련 (40 %), 검증 (10 %) 및 테스트 (50 %) 세트로 나뉘며, 검증 및 테스트 세트는 모두 어려움과 관련하여 "쉬움", "중간"및 "하드"하위 집합으로 나뉩니다. 탐지. 우리의 Pyramid Box는 훈련 세트에서만 훈련되고 [6,19–22,24–27,29,38,39와 같은 최첨단 얼굴 감지기와 비교하여 검증 세트와 테스트 세트 모두에서 평가됩니다. , 42,50,54,55]. 그림 7은 정밀도-재현율 곡선과 mAP 값을 보여줍니다. 우리의 피라미드 상자는 검증 세트의 경우 0.889 (어려움), 테스트 세트의 경우 0.956 (쉬움), 0.946 (중간), 0.887 (어려움)을 능가합니다.
5 Conclusion
This paper proposed a novel context-assisted single shot face detector, denoted as Pyramid Box, to handle the unconstrained face detection problem. We designed a novel context anchor, named Pyramid Anchor, to supervise face detector to learn features from contextual parts around faces. Besides, we modified feature pyramid network into a low-level feature pyramid network to combine features from high-level and high-resolution, which are effective for finding small faces. We also proposed a wider and deeper prediction module to make full use of joint feature. In addition, we introduced Data-anchor-sampling to augment the train data to increase the diversity of train data for small faces. The experiments demonstrate that our contributions lead Pyramid Box to the state-of-the-art performance on the common face detection benchmarks, especially for hard faces.
이 논문은 제약없는 얼굴 감지 문제를 처리하기 위해 Pyramid Box로 표시되는 새로운 상황 지원 단일 샷 얼굴 감지기를 제안했습니다. Pyramid Anchor라는 새로운 컨텍스트 앵커를 설계하여 얼굴 감지기를 감독하여 얼굴 주변의 컨텍스트 부분에서 특징을 학습했습니다. 또한 피처 피라미드 네트워크를 저수준 피처 피라미드 네트워크로 수정하여 작은 얼굴 찾기에 효과적인 고수준과 고해상도의 피처를 결합했습니다. 또한 관절 기능을 최대한 활용하기 위해 더 넓고 깊은 예측 모듈을 제안했습니다. 또한 작은 얼굴에 대한 열차 데이터의 다양성을 높이기 위해 열차 데이터를 보강하기 위해 데이터 앵커 샘플링을 도입했습니다. 실험은 우리의 기여가 Pyramid Box를 특히 딱딱한 얼굴에 대한 일반적인 얼굴 감지 벤치 마크에서 최첨단 성능으로 이끌었다는 것을 보여줍니다.
'지도학습 > 얼굴분석' 카테고리의 다른 글
| Data-Free Point Cloud Network for 3D Face Recognition (0) | 2021.03.29 |
|---|---|
| [ML]Haar Cascade classifier (0) | 2021.03.23 |
| 3D face recognition: a survey,2018 (0) | 2021.03.15 |
| Face recognition using Eigensurface on Kinect depth-maps,2016 (0) | 2021.03.15 |
| 3D Face Mesh Modeling from Range Images for 3D Face Recognition (0) | 2021.03.12 |



