SketchGAN: Joint Sketch Completion and Recognition with Generative Adversarial Network
SketchGAN : Generative Adversarial Network를 통한 공동 스케치 완성 및 인식
Abstract
Hand-drawn sketch recognition is a fundamental problem in computer vision, widely used in sketch-based image and video retrieval, editing, and reorganization. Previous methods often assume that a complete sketch is used as input; however, hand-drawn sketches in common application scenarios are often incomplete, which makes sketch recognition a challenging problem. In this paper, we propose SketchGAN, a new generative adversarial network (GAN) based approach that jointly completes and recognizes a sketch, boosting the performance of both tasks. Specifically, we use a cascade Encode-Decoder network to complete the input sketch in an iterative manner, and employ an auxiliary sketch recognition task to recognize the completed sketch. Experiments on the Sketchy database benchmark demonstrate that our joint learning approach achieves competitive sketch completion and recognition performance compared with the state-of-the-art methods. Further experiments using several sketch-based applications also validate the performance of our method.
손으로 그린 스케치 인식은 스케치 기반 이미지 및 비디오 검색, 편집 및 재구성에 널리 사용되는 컴퓨터 비전의 근본적인 문제입니다. 이전 방법은 종종 완전한 스케치가 입력으로 사용된다고 가정합니다. 그러나 일반적인 응용 시나리오에서 손으로 그린 스케치는 종종 불완전하여 스케치 인식이 어려운 문제가됩니다. 이 논문에서는 스케치를 공동으로 완성하고 인식하여 두 작업의 성능을 향상시키는 새로운 생성 적 적대 네트워크 (GAN) 기반 접근 방식 인 SketchGAN을 제안합니다. 특히 캐스케이드 인코더-디코더 네트워크를 사용하여 반복적 인 방식으로 입력 스케치를 완성하고 보조 스케치 인식 작업을 사용하여 완성 된 스케치를 인식합니다. Sketchy 데이터베이스 벤치 마크에 대한 실험은 당사의 공동 학습 접근 방식이 최첨단 방법과 비교하여 경쟁력있는 스케치 완성 및 인식 성능을 달성한다는 것을 보여줍니다. 여러 스케치 기반 응용 프로그램을 사용한 추가 실험도 우리 방법의 성능을 검증합니다.
1. Introduction
Sketch is a natural symbol to express abstract ideas in a straightforward way, which is widely used in computer vision [14, 27, 45], multimedia reorganization [7, 31] and human computer interactions [39]. Hand-drawn sketch recognition is a fundamental problem in many sketch-based applications. However, they are often incomplete, e.g., quick interim sketches, and sketches of multiple overlapping objects where some objects are partially occluded. In this paper, we explore the sketch completion problem, which will benefit related research such as sketch recognition, sketch editing and sketch-based image retrieval (SBIR).
스케치는 추상적 인 아이디어를 직관적으로 표현하는 자연스러운 상징으로 컴퓨터 비전 [14, 27, 45], 멀티미디어 재구성 [7, 31] 및 인간 컴퓨터 상호 작용 [39]에 널리 사용됩니다. 손으로 그린 스케치 인식은 많은 스케치 기반 응용 프로그램에서 근본적인 문제입니다. 그러나 빠른 중간 스케치와 일부 객체가 부분적으로 가려진 여러 겹치는 객체의 스케치와 같이 종종 불완전합니다. 이 백서에서는 스케치 인식, 스케치 편집 및 스케치 기반 이미지 검색 (SBIR)과 같은 관련 연구에 도움이 될 스케치 완성 문제를 살펴 봅니다.
Sketch completion aims to infer reasonable lines to fill in missing strokes in a sketch. An ideal sketch contains perceptually closure contour and uses a sparse set of lines to capture main shape characteristics. Although sketch recognition [17] and classification [47, 54] have achieved much progress in the last decade, little attention is paid to sketch completion. Hand-drawn sketches lack texture and contextual information, and are generally known to be more ambiguous than natural images. Therefore, image completion methods designed for color images do not work well for sketches directly. Moreover, the sketches of the same object may be drawn in diverse styles due to the nature of freehand sketches, which makes sketch completion very challenging.
스케치 완성은 스케치에서 누락 된 획을 채우기 위해 합리적인 선을 추론하는 것을 목표로합니다. 이상적인 스케치는 지각 적으로 마감 된 윤곽선을 포함하고 희소 한 선 세트를 사용하여 주요 모양 특성을 캡처합니다. 스케치 인식 [17]과 분류 [47, 54]가 지난 10 년 동안 많은 진전을 이루었지만 스케치 완성에는 거의 관심이 없습니다. 손으로 그린 스케치는 질감과 상황 정보가 부족하며 일반적으로 자연스러운 이미지보다 모호한 것으로 알려져 있습니다. 따라서 컬러 이미지 용으로 설계된 이미지 완성 방법은 스케치에 직접 적합하지 않습니다. 또한 프리 핸드 스케치의 특성상 동일한 개체의 스케치를 다양한 스타일로 그릴 수있어 스케치 완성이 매우 어렵습니다.
Sketch is closely related to contour, both of which are visually closed outlines of objects using black and white pixels. The major difference between sketch and contour is that contour always keeps consistent with the corresponding real image, while sketch has more diversity [13] and abstraction levels [36] in appearance. A lot of effort has been made on contour completion [34, 42, 50], aiming to either extract perceptually-salient contours from images or to find the boundaries of objects and surfaces in a scene. The contour completion methods cannot be applied to sketch completion directly since contour completion enforces accurate alignment with object boundaries in original images, while sketches are not associated with specific images.
스케치는 윤곽선과 밀접한 관련이 있으며 둘 다 흑백 픽셀을 사용하는 개체의 시각적으로 닫힌 윤곽선입니다. 스케치와 윤곽선의 주요 차이점은 윤곽선은 항상 해당 실제 이미지와 일관성을 유지하는 반면, 스케치는 모양이 더 다양하고 [13] 추상화 수준 [36]이라는 점입니다. 이미지에서 지각 적으로 두드러진 윤곽을 추출하거나 장면에서 물체와 표면의 경계를 찾기 위해 윤곽 완성 [34, 42, 50]에 많은 노력을 기울였습니다. 윤곽 완성 방법은 스케치 완성에 직접 적용 할 수 없습니다. 윤곽 완성은 원본 이미지의 객체 경계와 정확한 정렬을 강제하기 때문에 스케치는 특정 이미지와 연관되지 않습니다.
Another related problem is image completion. However, even the state-of-the-art convolutional neural network (CNN) based methods [18, 20] designed for image completion have poor performance on sketch completion due to the lack of color and texture context.
또 다른 관련 문제는 이미지 완성입니다. 그러나 이미지 완성을 위해 설계된 최첨단 컨볼 루션 신경망 (CNN) 기반 방법 [18, 20]조차도 색상과 텍스처 컨텍스트가 부족하여 스케치 완성시 성능이 떨어집니다.
In this paper, we propose a generative adversarial network (GAN) for sketch completion, called SketchGAN. Our method is not category specific, and can complete input sketches of different categories. Our key idea is to jointly conduct sketch completion and recognition tasks. The generator of our SketchGAN consists of a multi-stage cascade network, where each stage consists of a conditional GAN [21], and the cascade structure can further boost the performance of a single stage. The first stage uses an incomplete sketch as input, and transforms it to a roughly completed output. A later stage concatenates the original input and all the output sketches of the previous stages, and feeds them to the generator network in the current stage. Since we aim to design a general sketch completion framework suitable for multi-category sketch completion, motivated by multi-task learning in which auxiliary tasks can often improve the performance of the main task, we adopt sketch recognition as the auxiliary task. Conceptually, the high level recognition task benefits from the global context structure of the sketch completion results, and in turn training them together promotes better sketch completion.
이 논문에서는 SketchGAN이라는 스케치 완성을위한 생성 적 적대 네트워크 (GAN)를 제안합니다. 우리의 방법은 특정 카테고리가 아니며 다른 카테고리의 입력 스케치를 완료 할 수 있습니다. 우리의 핵심 아이디어는 스케치 완성 및 인식 작업을 공동으로 수행하는 것입니다. SketchGAN의 생성기는 다단계 캐스케이드 네트워크로 구성되며 각 단계는 조건부 GAN [21]으로 구성되며 캐스케이드 구조는 단일 단계의 성능을 더욱 향상시킬 수 있습니다. 첫 번째 단계에서는 불완전한 스케치를 입력으로 사용하고 대략 완성 된 출력으로 변환합니다. 이후 단계는 원래 입력과 이전 단계의 모든 출력 스케치를 연결하고 현재 단계의 발전기 네트워크에 공급합니다. 보조 과제가 주 과제의 성능을 향상시킬 수있는 다중 과제 학습을 모티브로하여 다중 카테고리 스케치 완성에 적합한 일반적인 스케치 완성 프레임 워크를 설계하고자하므로 스케치 인식을 보조 과제로 채택하고 있습니다. 개념적으로 높은 수준의 인식 작업은 스케치 완료 결과의 글로벌 컨텍스트 구조에서 이점을 얻고이를 함께 훈련하면 더 나은 스케치 완료를 촉진합니다.

Experiments on a widely-used dataset show that our method is superior to state-of-the-art methods, and the sketch completion and recognition tasks benefit each other. An example of our joint sketch completion and recognition is illustrated in Figure 1, which demonstrates the mutual benefits of addressing both tasks simultaneously. We further demonstrate that our method is very helpful to improve the performance of downstream applications such as incomplete sketch recognition and sketch editing.
널리 사용되는 데이터 세트에 대한 실험은 우리의 방법이 최첨단 방법보다 우수하고 스케치 완성 및 인식 작업이 서로에게 도움이된다는 것을 보여줍니다. 공동 스케치 완료 및 인식의 예가 그림 1에 나와 있으며, 두 작업을 동시에 처리 할 때의 상호 이점을 보여줍니다. 또한 우리의 방법이 불완전한 스케치 인식 및 스케치 편집과 같은 다운 스트림 애플리케이션의 성능을 향상시키는 데 매우 도움이된다는 것을 보여줍니다.
Our contributions are summarized as follows.
1. To the best of our knowledge, we are the first to solve the problem of sketch completion, which can inspire further sketch-based research.
2. We propose a new network architecture for sketch completion, namely SketchGAN, which handles sketches of different categories. Our method jointly conducts sketch completion and an auxiliary sketch recognition task, and we find that sketch completion and recognition tasks benefit each other.
3. Experiments demonstrate that the output of SketchGAN can enhance the performance of typical sketch applications such as incomplete sketch recognition and sketch editing.
우리의 기여는 다음과 같이 요약됩니다. 1. 우리가 아는 한, 우리는 스케치 완성 문제를 가장 먼저 해결하여 스케치 기반 연구에 영감을 줄 수 있습니다. 2. 스케치 완성을위한 새로운 네트워크 아키텍처 인 SketchGAN을 제안합니다.이 아키텍처는 다양한 카테고리의 스케치를 처리합니다. 우리의 방법은 스케치 완성과 보조 스케치 인식 작업을 공동으로 수행하며, 스케치 완성과 인식 작업이 서로에게 도움이된다는 것을 발견했습니다. 3. 실험은 SketchGAN의 출력이 불완전한 스케치 인식 및 스케치 편집과 같은 일반적인 스케치 응용 프로그램의 성능을 향상시킬 수 있음을 보여줍니다.
2. Related Work
Contour completion. Contour completion plays an important role in visual perception, and it aims to group fragmented low-level edge elements into perceptually coherent and salient contours [34]. Several learning based methods for edge detection are proposed recently [2, 57]. Xie et al. [48] use a convolutional network to pool information from the whole image. These local [23] or mid-level contour detection models [34, 42, 50] often ignore the important problem of contour closure, which has been widely studied more recently [35]. Instead of using segmentation, they propose a novel approach for contour completion that results in closure contour in the contour domain. Our paper focuses on sketch completion, which aims to inpaint corrupted sketches or hand-drawn lines with missing lines instead of extracting edges from natural images in contour completion. Sketch completion is more challenging than contour completion, due to the ambiguity nature, large variations and different abstraction levels among sketches.
윤곽 완성.
윤곽 완성은 시각적 인식에서 중요한 역할을하며 조각난 저수준 가장자리 요소를 지각 적으로 일관되고 두드러진 윤곽으로 그룹화하는 것을 목표로합니다 [34]. 최근 에지 탐지를위한 몇 가지 학습 기반 방법이 제안되었습니다 [2, 57]. Xie et al. 컨볼 루션 네트워크를 사용하여 전체 이미지에서 정보를 풀링합니다. 이러한 로컬 [23] 또는 중간 수준의 윤곽선 감지 모델 [34, 42, 50]은 종종 최근에 광범위하게 연구 된 윤곽 폐쇄의 중요한 문제를 무시합니다 [35]. 세분화를 사용하는 대신, 그들은 윤곽 영역에서 폐쇄 윤곽을 생성하는 윤곽 완성을위한 새로운 접근 방식을 제안합니다. 우리의 논문은 윤곽 완성에서 자연스러운 이미지에서 가장자리를 추출하는 대신 손상된 스케치 나 손으로 그린 선에 누락 된 선을 칠하는 것을 목표로하는 스케치 완성에 중점을 둡니다. 모호성, 큰 변형 및 스케치 간의 다양한 추상화 수준으로 인해 스케치 완성은 윤곽 완성보다 더 어렵습니다.
Image completion.
Another related problem to sketch completion is image completion, both of which aim to fill in missing strokes or regions. Previous image completion methods can be classified into diffusion-based image synthesis and patch-based methods. Diffusion-based methods apply filters to propagate the local image appearance near the target regions to fill them [4, 25]. Patch-based approaches are proposed for larger missing areas and complicated image completion [12, 18, 24]. Unfortunately, depending on the hand-crafted features, these traditional image completion approaches can only repair small corrupted areas, and cannot generate new objects which do not exist in the original corrupted images. Recently, convolutional networks have been applied to image completion [37, 51]. A joint multiplanar autoregressive and low-rank based approach has been proposed for image completion from random sampling [26]. Beak et al. [3] present a multiview image completion method that provides geometric consistency among different views by propagating spatial structures. Sketch completion and image completion both belong to generative models. Compared to image completion, sketch completion is more challenging due to the fact that handdrawn sketches lack color and contextual information for sketch understanding. Although these image completion methods work very well on incomplete natural images, they are not suitable for the sketch completion task due to the style and content gap between natural images and sketches.
이미지 완성.
스케치 완성과 관련된 또 다른 문제는 이미지 완성이며, 둘 다 누락 된 획이나 영역을 채우는 것을 목표로합니다. 기존의 영상 완성 방식은 확산 기반 영상 합성과 패치 기반 방식으로 구분할 수 있습니다. 확산 기반 방법은 필터를 적용하여 대상 영역 근처의 로컬 이미지 모양을 전파하여 채 웁니다 [4, 25]. 더 큰 누락 영역과 복잡한 이미지 완성을 위해 패치 기반 접근 방식이 제안됩니다 [12, 18, 24]. 안타깝게도 손으로 만든 기능에 따라 이러한 전통적인 이미지 완성 방법은 작은 손상된 영역 만 복구 할 수 있으며 원래 손상된 이미지에없는 새 개체를 생성 할 수 없습니다. 최근에는 이미지 완성에 컨볼 루션 네트워크가 적용되었습니다 [37, 51]. 무작위 샘플링에서 이미지 완성을 위해 공동 다중 평면 자기 회귀 및 낮은 순위 기반 접근법이 제안되었습니다 [26]. Beak et al. [3]은 공간 구조를 전파하여 서로 다른 시점 간의 기하학적 일관성을 제공하는 다시 점 영상 완성 방법을 제시한다. 스케치 완성과 이미지 완성은 모두 생성 모델에 속합니다. 손으로 그린 스케치에는 스케치 이해를위한 색상 및 상황 정보가 부족하기 때문에 이미지 완성에 비해 스케치 완성이 더 어렵습니다. 이러한 이미지 완성 방법은 불완전한 자연 이미지에서 매우 잘 작동하지만 자연 이미지와 스케치 사이의 스타일 및 콘텐츠 차이로 인해 스케치 완성 작업에는 적합하지 않습니다.
Generative adversarial networks (GANs). GANs [15] achieved impressive results for image generation [5], image completion [20], and image editing [38]. GAN trains two networks, a generative model G and a discriminative model D. Upon convergence, D can reject images that look fake, and G can produce high-quality images, which can fool D. A variety of GANs have been proposed for im age translation problems, such as DA-GAN [32], TP-GAN [19], and starGAN [10]. Pix2Pix [21] investigates using conditional adversarial networks as a general-purpose solution to image-to-image translation problems. CycleGAN [56] introduces a cycle consistency loss to learn a mapping from a source domain to a target domain without paired training examples. Conditional GANs have been applied to text [55, 41], images [1], and sketches [29]. In the sketch understanding field, conditional GANs are successfully applied to enhance the performance of sketch recognition [11], SBIR [16], and sketch-based image generation [8].
GANs [15]는 이미지 생성 [5], 이미지 완성 [20], 이미지 편집 [38]에서 인상적인 결과를 얻었습니다. GAN은 생성 모델 G와 차별 모델 D라는 두 개의 네트워크를 훈련시킵니다. 수렴시 D는 가짜로 보이는 이미지를 거부 할 수 있고 G는 D를 속일 수있는 고품질 이미지를 생성 할 수 있습니다. 이미지를 위해 다양한 GAN이 제안되었습니다. DA-GAN [32], TP-GAN [19] 및 starGAN [10]과 같은 번역 문제. Pix2Pix [21]는 조건부 적대 네트워크를 이미지 대 이미지 변환 문제에 대한 범용 솔루션으로 사용하는 방법을 조사합니다. CycleGAN [56]은 쌍을 이룬 학습 예제없이 소스 도메인에서 대상 도메인으로의 매핑을 학습하기 위해주기 일관성 손실을 도입했습니다. 조건부 GAN은 텍스트 [55, 41], 이미지 [1], 스케치 [29]에 적용되었습니다. 스케치 이해 분야에서는 스케치 인식 [11], SBIR [16], 스케치 기반 이미지 생성 [8]의 성능을 향상시키기 위해 조건부 GAN이 성공적으로 적용되었습니다.
Multi-task networks. 다중 작업 네트워크.
Multi-task CNN models are widely used in various image processing [28, 6, 49] and computer vision [22, 30, 49] applications. Motivated by the idea that the best task estimator could change depending on the task itself, Mejjati et al. [33] present a new multi-task learning approach that can be applied to multiple heterogeneous task estimators. Kiran et al. [45] propose SketchParse for automatic parsing of freehand object sketches. The architecture incorporates object pose prediction as a novel auxiliary task to enhance the overall sketch parsing performance. In this paper, we explore to learn sketch completion using sketch category recognition as an auxiliary task. Our method differs from these previous works in several aspects. To the best of our knowledge, we are the first to conduct systematic studies on sketch completion, which cannot be well solved by existing image completion methods. We further propose a cascade strategy for generative adversarial networks, which iteratively refines the sketch completion results. Most importantly, we solve the sketch completion and sketch recognition problems jointly, and experiments show that these two tasks can benefit each other.
멀티 태스킹 CNN 모델은 다양한 이미지 처리 [28, 6, 49] 및 컴퓨터 비전 [22, 30, 49] 애플리케이션에서 널리 사용됩니다. 작업 자체에 따라 최상의 작업 추정기가 바뀔 수 있다는 생각에 동기를 부여한 Mejjati et al. [33]은 여러 이기종 작업 추정기에 적용될 수있는 새로운 다중 작업 학습 접근법을 제시합니다. Kiran et al. [45] 자유형 개체 스케치의 자동 구문 분석을위한 SketchParse를 제안합니다. 이 아키텍처는 전체 스케치 구문 분석 성능을 향상시키기 위해 새로운 보조 작업으로 객체 포즈 예측을 통합합니다. 이 백서에서는 스케치 범주 인식을 보조 작업으로 사용하여 스케치 완성에 대해 알아 봅니다. 우리의 방법은 여러 측면에서 이전 작업과 다릅니다. 우리가 아는 한, 기존 이미지 완성 방법으로는 해결할 수없는 스케치 완성에 대한 체계적인 연구를 최초로 수행합니다. 또한 스케치 완성 결과를 반복적으로 개선하는 생성 적 적 네트워크에 대한 캐스케이드 전략을 제안합니다. 가장 중요한 것은 스케치 완성 및 스케치 인식 문제를 공동으로 해결하고 실험을 통해이 두 작업이 서로에게 도움이 될 수 있음을 보여줍니다.
3. Methodology

The architecture of our sketch completion network SketchGAN is shown in Figure 2. Briefly speaking, given an incomplete sketch x as input, our architecture iteratively refines it through multiple stages (3 stages in the illustration). At each stage, the generator G takes the input x and outputs from the previous stages (if applicable) and produces a better completed sketch G(x). The generated sketch image G(x) of the last stage is judged by the discriminator network D to be real or fake. Finally, we set a sketch recognition network as an auxiliary network to improve the main target of sketch completion.
스케치 완성 네트워크 SketchGAN의 아키텍처는 그림 2에 나와 있습니다. 간단히 말하면 불완전한 스케치 x가 입력으로 주어지면 아키텍처는 여러 단계 (그림의 3 단계)를 통해 반복적으로 개선합니다. 각 단계에서 생성기 G는 이전 단계 (해당되는 경우)에서 입력 x와 출력을 가져와 더 잘 완성 된 스케치 G (x)를 생성합니다. 마지막 단계에서 생성 된 스케치 이미지 G (x)는 판별 기 네트워크 D에 의해 실제 또는 가짜로 판단됩니다. 마지막으로 스케치 완성의 주요 목표를 개선하기 위해 스케치 인식 네트워크를 보조 네트워크로 설정했습니다.
3.1. GAN and Recognition Losses
Our approach is based on generative adversarial networks (GANs) [15]. A GAN is a generative model that learns a mapping from a random noise vector z to an output image y : G : z → y . In contrast, a conditional GAN learns a mapping from observed image x and random noise vector z to an output image y : G : {x, z} → y . Denote by pz and pdata the prior distributions of z and the real data x. The objective of a conditional GAN can be formulated as: LcGAN (G, D) = Ex,y∼pdata(x,y) [log D(x, y)] + Ex∼pdata(x),z∼pz(z) [log(1 − D(x, G(x, y))], where a generator G is trained to minimize this objective against an adversarial D that tries to maximize it, i.e. G ∗ = arg min G max D LcGAN (G, D). We further utilize the improved loss proposed by Pix2Pix [21] in which the discriminator does not observe x and an l1 distance is mixed with the GAN objective to encourage less blurring: LcGAN (G, D) = Ey∼pdata(y) [log D(x, y)] + Ex∼pdata(x),z∼pz(z) [log(1 − D(x, G(x, y))], LL1(G) = Ex,y,z[||y − G(x, z)||1]. The auxiliary sketch recognition loss maximizes the loglikelihood between predicted and ground-truth labels: Lac(C) = E[log P(C = c|y)] and the generator maximizes the same log-likelihood Lac(G) with the discriminator and classifier fixed. Our total loss function is defined as follows: G ∗ = arg min G max D LcGAN (G, D)+λ1LL1(G)+λ2Lac(G), where λ1 and λ2 are weights to balance different loss terms. We empirically set λ1 = 100 and λ2 = 0.5, which give good performance. In addition, we make our final network learn a mapping from x to y without z, which is consistent with Pix2Pix [21]. We only apply noise on several layers of the generator in the form of dropout.
우리의 접근 방식은 GAN (Generative Adversarial Network) [15]을 기반으로합니다. GAN은 임의의 노이즈 벡터 z에서 출력 이미지 y : G : z → y 로의 매핑을 학습하는 생성 모델입니다. 대조적으로, 조건부 GAN은 관찰 된 이미지 x와 랜덤 노이즈 벡터 z에서 출력 이미지 y : G : {x, z} → y 로의 매핑을 학습합니다. z와 실제 데이터 x의 사전 분포를 pz 및 pdata로 표시합니다. 조건부 GAN의 목적은 다음과 같이 공식화 할 수 있습니다. LcGAN (G, D) = Ex, y ~ pdata (x, y) [log D (x, y)] + Ex ~ pdata (x), z ~ pz (z ) [log (1 − D (x, G (x, y)))], 여기서 생성기 G는이를 최대화하려는 적대 D에 대해이 목표를 최소화하도록 훈련됩니다. 즉 G ∗ = arg min G max D LcGAN ( G, D). 우리는 식별기가 x를 관찰하지 않고 l1 거리가 GAN 목표와 혼합되는 Pix2Pix [21]에서 제안한 개선 된 손실을 활용하여 블러 링을 줄입니다. LcGAN (G, D) = Ey∼pdata (y) [log D (x, y)] + Ex∼pdata (x), z∼pz (z) [log (1 − D (x, G (x, y))], LL1 (G) = Ex , y, z [|| y − G (x, z) || 1] 보조 스케치 인식 손실은 예측 레이블과 실측 레이블 간의 로그 가능성을 최대화합니다. Lac (C) = E [log P (C = c | y)]와 생성기는 판별 기와 분류기를 고정한 상태에서 동일한 로그 우도 Lac (G)를 최대화합니다. 총 손실 함수는 다음과 같이 정의됩니다. G ∗ = arg min G max D LcGAN (G, D) + λ1LL1 (G ) + λ2Lac (G), 여기서 λ1과 λ2는 균형을 맞추기위한 가중치입니다. 손실 조건. 경험적으로 λ1 = 100 및 λ2 = 0.5로 설정하여 좋은 성능을 제공합니다. 또한 최종 네트워크가 z없이 x에서 y 로의 매핑을 학습하게하는데 이는 Pix2Pix [21]와 일치합니다. 우리는 드롭 아웃 형태로 발생기의 여러 레이어에만 노이즈를 적용합니다.
3.2. Cascade Strategy
We propose a cascade module to further refine the contour closure of the completed sketches and boost the baseline performance, which can be trained in a multi-stage manner and keeps a good balance between accuracy and efficiency. Our method uses sequential iterations for refinement, starting from an initial model output, and then refining the output by iteratively using original input and all the outputs of the previous stages. Each cascade stage is built upon a conditional GAN network, but does not share network parameters for different cascade stages. More specifically, the output of the first cascade stage y1 is fed to the next cascade stage, together with the original corrupted sketch image x. The output of the second cascade stage y2 is fed to the third cascade stage, together with the original corrupted sketch image x and the output of the first cascade stage y1. Experiments of the proposed network on the Sketchy database [44] over the number of cascade stages have been conducted, and the performance of the network is almost reaching a steady state after three cascade iterations. This cascade network can be regarded as a recurrent completion process since both the original input x and the intermediate outputs are repeatedly fed to the generator. The outputs are not fed to the discriminator or the classification network until the last cascade stage.
3.2. 캐스케이드 전략
완성된 스케치의 윤곽 마감을 더욱 세분화하고 기준 성능을 향상시키는 캐스케이드 모듈을 제안합니다. 이는 다단계 방식으로 훈련 할 수 있으며 정확성과 효율성 사이의 균형을 잘 유지합니다. 우리의 방법은 초기 모델 출력에서 시작하여 원래 입력과 이전 단계의 모든 출력을 반복적으로 사용하여 출력을 미세 조정하기 위해 순차적 반복을 사용합니다. 각 캐스케이드 단계는 조건부 GAN 네트워크에 구축되지만 다른 캐스케이드 단계에 대한 네트워크 매개 변수를 공유하지 않습니다. 보다 구체적으로, 첫 번째 캐스케이드 단계 y1의 출력은 원래 손상된 스케치 이미지 x와 함께 다음 캐스케이드 단계로 공급됩니다. 두 번째 캐스케이드 단계 y2의 출력은 원래 손상된 스케치 이미지 x 및 첫 번째 캐스케이드 단계 y1의 출력과 함께 세 번째 캐스케이드 단계로 공급됩니다. Sketchy 데이터베이스에서 제안 된 네트워크 [44]의 캐스케이드 단계 수에 대한 실험이 수행되었으며 네트워크의 성능은 세 번의 캐스케이드 반복 후에 거의 정상 상태에 도달하고 있습니다. 이 캐스케이드 네트워크는 원래 입력 x와 중간 출력이 모두 발전기에 반복적으로 공급되기 때문에 반복 완료 프로세스로 간주 될 수 있습니다. 출력은 마지막 캐스케이드 단계까지 판별 기 또는 분류 네트워크에 공급되지 않습니다.
3.3. Sketch Recognition
We adopt a sketch recognition network C as an auxiliary network for sketch completion. The architecture for C is shown within the top-right box in Figure 2. The motivation to use sketch recognition as an auxiliary task is as follows. On the one hand, completed sketches help improve sketch recognition performance. Although sketch recognition has been widely studied, the problem of corrupted sketch recognition is hardly researched. As we will show later in Section 4, the output of our sketch completion method improves the performance of existing sketch recognition algorithms. On the other hand, since correctly completed sketches are easier to classify, this in turn promotes better sketch completion. Experiments show that the completion results with the auxiliary sketch recognition task are better than those without the sketch recognition task.
3.3. 스케치 인식
스케치 완성을위한 보조 네트워크로 스케치 인식 네트워크 C를 채택했습니다. C의 아키텍처는 그림 2의 오른쪽 상단 상자에 표시되어 있습니다. 스케치 인식을 보조 작업으로 사용하는 동기는 다음과 같습니다. 한편으로 완성 된 스케치는 스케치 인식 성능을 향상시키는 데 도움이됩니다. 스케치 인식이 광범위하게 연구되었지만 손상된 스케치 인식 문제는 거의 연구되지 않았습니다. 나중에 섹션 4에서 설명 하겠지만, 스케치 완성 방법의 출력은 기존 스케치 인식 알고리즘의 성능을 향상시킵니다. 반면에 올바르게 완성 된 스케치는 분류하기가 더 쉬우므로 스케치 완성도 향상됩니다. 실험은 보조 스케치 인식 작업을 사용한 완료 결과가 스케치 인식 작업이없는 경우보다 낫다는 것을 보여줍니다.
3.4. Network Architecture
Generator.
Following the generator architecture from those in [21], skip connections between mirrored layers in the encoder and decoder stacks have been added to the generator, following the general shape of a “U-Net” [43]. Our inputs are the fused information of the original input and the outputs of the previous stages. The inputs are fed to a preprocessing network consisting of two convolutional layers. We use eight up-convolutional layers with kernel size 4 and stride 2. A batch normalization layer and a rectified linear unit (ReLU) activation is used in all layers. Instead of a sigmoid activation used in the output layer in Pix2Pix, we use a tanh activation and then map it to [0, 1] in the output.
[21]의 생성기 아키텍처에 따라 "U-Net"[43]의 일반적인 형태에 따라 인코더 및 디코더 스택의 미러링 된 레이어 간의 스킵 연결이 생성기에 추가되었습니다. 우리의 입력은 원래 입력과 이전 단계의 출력의 융합 된 정보입니다. 입력은 두 개의 컨벌루션 계층으로 구성된 전처리 네트워크에 공급됩니다. 커널 크기가 4이고 스트라이드 2 인 8 개의 업 컨벌루션 레이어를 사용합니다. 배치 정규화 레이어와 ReLU (rectified linear unit) 활성화는 모든 레이어에서 사용됩니다. Pix2Pix의 출력 레이어에서 사용되는 시그 모이 드 활성화 대신 tanh 활성화를 사용한 다음 출력에서 [0, 1]에 매핑합니다.
Discriminator.
Inspired by the work [20], we use two components in the discriminator network. The local discriminator tells the fake sketch image from the real one only concentrating on the completed local regions, while the global discriminator focuses on the coherence of the entire image and the contour closure effect. Outputs of the networks are fused together by a concatenation layer, followed by a fully connected layer and activated by a ReLU function. Finally, we use a tanh activation and then map the result to [0, 1] in the output, in which 0 means fake and 1 means real.
작업 [20]에서 영감을 받아 우리는 판별 기 네트워크에서 두 가지 구성 요소를 사용합니다. 로컬 판별 기는 완성 된 로컬 영역에만 집중된 실제 스케치 이미지와 가짜 스케치 이미지를 알려주고, 글로벌 판별 기는 전체 이미지의 일관성과 윤곽 마감 효과에 중점을 둡니다. 네트워크의 출력은 연결 계층에 의해 융합되고, 그 다음에는 완전히 연결된 계층이 뒤 따르고 ReLU 기능에 의해 활성화됩니다. 마지막으로 tanh 활성화를 사용한 다음 결과를 출력의 [0, 1]에 매핑합니다. 여기서 0은 가짜를 의미하고 1은 실제를 의미합니다.
Classifier.
We have adopted Sketch-a-Net [53] as our sketch recognition auxiliary network C. Sketch-a-Net is a state-of-the-art CNN model for freehand sketch recognition. The network architecture of C is shown in the top-right box in Figure 2. The sketch recognition auxiliary network is trained using a cross-entropy loss in an end-to-end manner along with the rest of SketchGAN.
Sketch-a-Net [53]을 스케치 인식 보조 네트워크 C로 채택했습니다. Sketch-a-Net은 자유형 스케치 인식을위한 최첨단 CNN 모델입니다. C의 네트워크 아키텍처는 그림 2의 오른쪽 상단 상자에 나와 있습니다. 스케치 인식 보조 네트워크는 나머지 SketchGAN과 함께 종단 간 방식으로 교차 엔트로피 손실을 사용하여 훈련됩니다.
4. Experiments and Results
4.1. Dataset and Evaluation Metrics
Dataset.
The Sketchy database (Sketchy) [44] is the first large-scale collection of sketch-photo pairs. Particular photographic objects sampled from 125 categories have been sketched by crowd workers and totally 75,471 sketches of 12,500 objects have been acquired. This database is widely used in fine-grained sketch-related applications.
4. 실험 및 결과
4.1. 데이터 세트 및 평가 지표
데이터 세트.
Sketchy 데이터베이스 (Sketchy) [44]는 스케치-사진 쌍의 첫 번째 대규모 컬렉션입니다. 125 개 카테고리에서 샘플링 된 특정 사진 개체는 군중 작업자가 스케치했으며 총 12,500 개 개체의 75,471 개 스케치를 획득했습니다. 이 데이터베이스는 세분화 된 스케치 관련 응용 프로그램에서 널리 사용됩니다.
Data Preprocessing. 데이터 전처리.
We conduct data augmentation on the Sketchy database by making randomly corrupted sketches for each category. The dataset is randomly split into training and testing sets, containing 80% and 20% sketches, respectively. For each sketch, we generate a blank rectangle mask of random size and random position to erase the original sketch and get a corrupted sketch. This corrupted sketch is saved in the database if the difference between the original sketch and the corrupted sketch is within 10% ∼ 40%, to simulate typical missing content on sketches. We generate one corrupted sketch for each sketch and finally obtain about 500 corrupted sketches for each category.
우리는 각 카테고리에 대해 무작위로 손상된 스케치를 만들어 Sketchy 데이터베이스에서 데이터 보강을 수행합니다. 데이터 세트는 각각 80 % 및 20 % 스케치를 포함하는 훈련 및 테스트 세트로 무작위로 분할됩니다. 각 스케치에 대해 임의의 크기와 임의의 위치의 빈 사각형 마스크를 생성하여 원본 스케치를 지우고 손상된 스케치를 얻습니다. 이 손상된 스케치는 원본 스케치와 손상된 스케치의 차이가 10 % ~ 40 % 이내 인 경우 데이터베이스에 저장되어 스케치에서 일반적인 누락 된 내용을 시뮬레이션합니다. 각 스케치에 대해 하나의 손상된 스케치를 생성하고 마지막으로 각 범주에 대해 약 500 개의 손상된 스케치를 얻습니다.
Our sketch completion network design is flexible to cope with arbitrary number of sketch categories. We perform ablation experiments and comparisons with the state-ofthe-art methods on 11 sketch sub-categories (car (sedan), cow, horse, cat, dog, sheep, airplane, motorcycle, bicycle, songbird, pickup truck) of Sketchy [44]. These subcategories are consistent with those in the SKETCHPARSE network [45] designed for general sketch parsing work.1 Moreover, we also conduct sketch completion on larger numbers of sketch categories, and experiments show that our model has stable performance even with all the 125 categories from the Sketchy database.
당사의 스케치 완성 네트워크 설계는 임의의 수의 스케치 범주에 유연하게 대처할 수 있습니다. Sketchy의 11 개 스케치 하위 카테고리 (자동차 (세단), 소, 말, 고양이, 개, 양, 비행기, 오토바이, 자전거, 송 버드, 픽업 트럭)에 대해 최첨단 방법으로 절제 실험 및 비교를 수행합니다. 44]. 이러한 하위 범주는 일반적인 스케치 구문 분석 작업을 위해 설계된 SKETCHPARSE 네트워크 [45]의 범주와 일치합니다 .1 또한 더 많은 수의 스케치 범주에 대해 스케치 완성을 수행하고 실험 결과 125 개 범주 모두에서도 모델이 안정적인 성능을 가지고 있음을 보여줍니다. Sketchy 데이터베이스에서.
Evaluation Metrics. 평가 지표.

To begin with, we adopt a straightforward pixel-to-pixel comparison method. We only compute the metrics within the corrupt mask. Four widely used metrics, i.e., the precision of completed black pixels Precision, the recall of completed black pixels Recall, the F-measure F-Measure, and the accuracy Accuracy, are computed. This pixel-to-pixel comparison method is not perfect for measuring the performance of sketch completion due to the inevitable variation of appropriate sketches. Ultimately, the goal of sketch completion is to make the generated sketches 1 In fact, the SKETCHPARSE used the data from TU-Berlin, and the two categories bus and bird cannot be found in Sketchy. Here we use the car (sedan) and songbird instead. plausible to humans. Generated sketches that do not match the original sketches used to make them, have relatively low Precision or Recall, but they may still be good (see Figure 3). Thus, we also visually inspect the results and conduct two user studies (refer to Section 4.5).
우선, 우리는 간단한 픽셀 대 픽셀 비교 방법을 채택합니다. 손상된 마스크 내의 메트릭 만 계산합니다. 4 개의 널리 사용되는 메트릭, 즉 완성 된 검은 색 픽셀 정밀도, 완성 된 검은 색 픽셀 재현율, F- 측정 F- 측정 및 정확도 정확도가 계산됩니다. 이 픽셀 대 픽셀 비교 방법은 적절한 스케치의 불가피한 변형으로 인해 스케치 완료 성능을 측정하는 데 완벽하지 않습니다. 궁극적으로 스케치 완성의 목표는 생성 된 스케치를 만드는 것입니다. 1 실제로 SKETCHPARSE는 TU-Berlin의 데이터를 사용했으며 두 범주 버스와 새는 Sketchy에서 찾을 수 없습니다. 여기서는 차 (세단)와 송 버드를 대신 사용합니다. 인간에게 그럴듯합니다. 제작에 사용 된 원본 스케치와 일치하지 않는 생성 된 스케치는 정밀도 또는 재현율이 비교적 낮지 만 여전히 양호 할 수 있습니다 (그림 3 참조). 따라서 결과를 시각적으로 검사하고 두 가지 사용자 연구를 수행합니다 (4.5 절 참조).
4.2. Sketch Completion Results
Comparative Results.

In this section, we show sketch completion results of the mentioned 11 object categories. Table 1 shows the quantitative performance of different categories in the Sketchy database. Each category contains about 550 sketches, and we make one corrupted sketch for each original sketch. Thus, the total numbers of training and testing corrupted sketches for all the 11 categories are 6,196 and 1,184, respectively.
4.2. 스케치 완료 결과 비교 결과. 이 섹션에서는 언급 된 11 개 개체 범주의 스케치 완료 결과를 보여줍니다. 표 1은 Sketchy 데이터베이스에있는 여러 범주의 정량적 성능을 보여줍니다. 각 카테고리에는 약 550 개의 스케치가 포함되어 있으며 각 원본 스케치에 대해 하나의 손상된 스케치를 만듭니다. 따라서 11 개 범주 모두에 대한 교육 및 테스트 손상된 스케치의 총 수는 각각 6,196 개와 1,184 개입니다.
Ablation study.
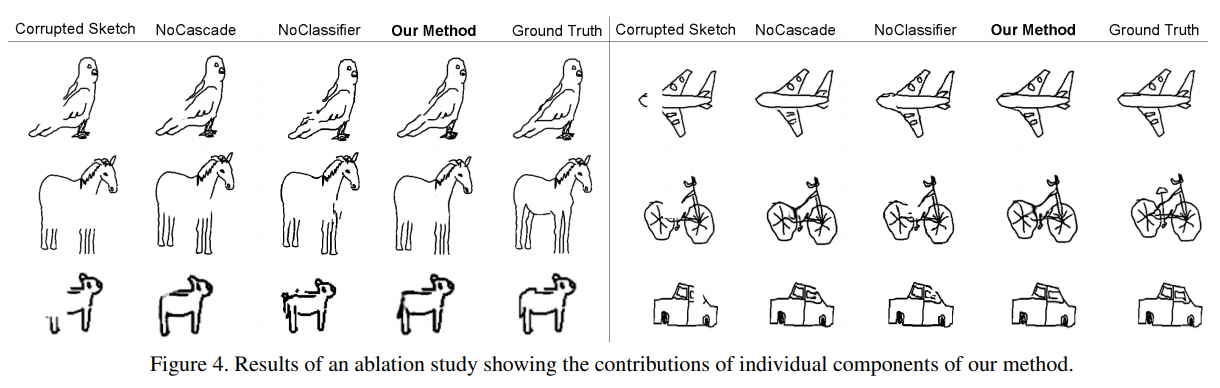

Compared to conventional photo-oriented DNNs such as Pix2Pix and DCGANs, our SketchGAN has two distinct features (see Section 3): (i) the cascade network architecture, (ii) the strategy of utilizing the auxiliary sketch recognition network. In this section we evaluate the contributions of each feature. Specifically, we examine three ablative versions of our full model: SketchGAN with all features but no cascade (No Cascade), SketchGAN with all features but no auxiliary sketch recognition network (No Classifier), i.e. there are no class labels and the data of 11 categories are trained and tested together, and SketchGAN with all features. We show the sketch completion results in Figure 4 for visual analysis. And the results in Table 2 show that both strategies contribute to the final strong performance of SketchGAN. In particular, (i) from the visual results, more broken lines and intermediate completed sketches are likely to be produced without the proposed cascade strategy, and the cascade strategy leads to better completion results on large corrupted regions. (ii) The auxiliary sketch recognition network improves the sketch completion greatly when multi-class objects exist by offering strong category priors. Experiments demonstrate that our sketch completion method can achieve reliable sketch completion results. The cascade strategy helps to make the completed sketches maintain contour closure, and the completion results tend to be distorted without the sketch recognition auxiliary network.
절제 연구.
Pix2Pix 및 DCGAN과 같은 기존의 사진 지향 DNN과 비교하여 SketchGAN은 (섹션 3 참조) (i) 캐스케이드 네트워크 아키텍처, (ii) 보조 스케치 인식 네트워크 활용 전략의 두 가지 특징을 가지고 있습니다. 이 섹션에서는 각 기능의 기여도를 평가합니다. 구체적으로, 우리는 전체 모델의 세 가지 절제 버전을 검사합니다. 모든 기능이 있지만 캐스케이드가없는 SketchGAN (캐스케이드 없음), 모든 기능이 있지만 보조 스케치 인식 네트워크가없는 SketchGAN (분류 자 없음), 즉 클래스 레이블과 11 개의 데이터가 없습니다. 카테고리는 함께 훈련되고 테스트되며 모든 기능을 갖춘 SketchGAN입니다. 시각적 분석을 위해 그림 4에 스케치 완료 결과를 보여줍니다. 그리고 표 2의 결과는 두 전략이 SketchGAN의 최종 강력한 성능에 기여한다는 것을 보여줍니다. 특히, (i) 시각적 결과에서 제안 된 캐스케이드 전략없이 더 많은 파선과 중간 완성 된 스케치가 생성 될 가능성이 높으며 캐스케이드 전략은 큰 손상된 영역에서 더 나은 완료 결과를 가져옵니다. (ii) 보조 스케치 인식 네트워크는 강력한 카테고리 사전을 제공하여 다중 클래스 객체가 존재할 때 스케치 완성을 크게 향상시킵니다. 실험은 스케치 완성 방법이 신뢰할 수있는 스케치 완성 결과를 얻을 수 있음을 보여줍니다. 캐스케이드 전략은 완성 된 스케치가 윤곽 마감을 유지하는 데 도움이되며 스케치 인식 보조 네트워크 없이는 완성 결과가 왜곡되는 경향이 있습니다.
Since the network directly outputs the inpainted sketches instead of filling holes, the output sketches may be different from the input on non-missing regions. We conduct evaluations on non-missing regions. Experiments of our SketchGAN show that non-missing regions are well preserved, with 93.46% precision and 85.72% recall.
네트워크가 구멍을 채우는 대신 색칠 된 스케치를 직접 출력하기 때문에 출력 스케치는 누락되지 않은 영역의 입력과 다를 수 있습니다. 누락되지 않은 영역에 대한 평가를 수행합니다. SketchGAN의 실험은 93.46 %의 정밀도와 85.72 %의 재현율로 비결 측 영역이 잘 보존되어 있음을 보여줍니다.
Network performance analysis. 네트워크 성능 분석.


We conduct experiments to evaluate the performance with respect to different incomplete ratios of corrupted sketches. In this experiment, we conduct a series of comparisons under the same conditions but with different incomplete ratios. Table 3 shows that our algorithm has good sketch completion performance under different incomplete levels. If the incomplete ratio is up to 40%, our sketch completion method performs well. When the incomplete ratio is above 40%, which is quite extreme in practical applications, the performance of our model drops. Moreover, we also conduct experiments to evaluate the performance with respect to different numbers of sketch categories. In this experiment, we conduct a series of comparisons under the same conditions but with gradually increased sketch categories. Table 4 shows our algorithm has good sketch completion performance under different numbers of sketch categories, and our method behaves well even for all the 125 sketch categories in the Sketchy Database. Therefore, our method also has good generalization power.
손상된 스케치의 서로 다른 불완전한 비율에 대한 성능을 평가하기 위해 실험을 수행합니다. 이 실험에서는 동일한 조건에서 불완전한 비율이 다른 일련의 비교를 수행합니다. 표 3은 알고리즘이 다양한 불완전 수준에서 좋은 스케치 완성 성능을 가지고 있음을 보여줍니다. 불완전 비율이 최대 40 %이면 스케치 완성 방법이 잘 수행됩니다. 불완전한 비율이 실제 응용에서 매우 극단적 인 40 %를 초과하면 모델의 성능이 저하됩니다. 또한 다양한 수의 스케치 범주에 대한 성능을 평가하기위한 실험도 수행합니다. 이 실험에서는 동일한 조건에서 스케치 범주를 점차 증가시켜 일련의 비교를 수행합니다. 표 4는 알고리즘이 다양한 수의 스케치 범주에서 좋은 스케치 완성 성능을 가지고 있음을 보여 주며, 우리의 방법은 Sketchy Database의 모든 125 스케치 범주에 대해서도 잘 작동합니다. 따라서 우리의 방법은 또한 좋은 일반화 능력을 가지고 있습니다.
4.3. Comparison with state-of-the-art methods
We compare our method with state-of-the-art methods: Pix2Pix [21], DCGAN [40], GlobalLocalImageCompletion [20], Generative Image Inpainting [52]. Pix2Pix and DCGAN are GAN-based methods, and GlobalLocalImageCompletion and Generative Image Inpainting are image inpainting methods.
4.3. 최첨단 방법과의 비교 우리의 방법을 Pix2Pix [21], DCGAN [40], GlobalLocalImageCompletion [20], Generative Image Inpainting [52]과 같은 최첨단 방법과 비교합니다. Pix2Pix 및 DCGAN은 GAN 기반 메서드이고 GlobalLocalImageCompletion 및 Generative Image Inpainting은 이미지 inpainting 메서드입니다.
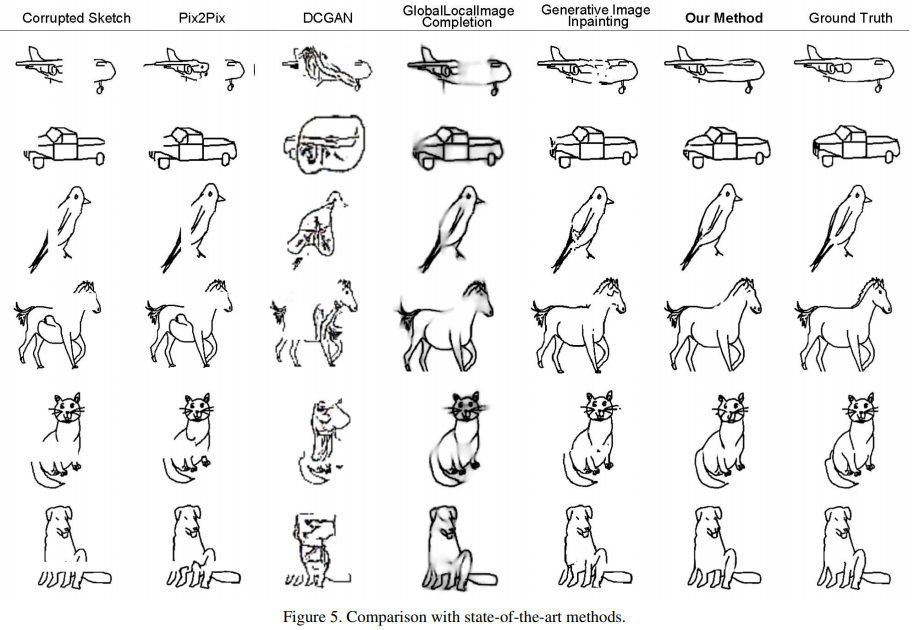

Table 5 shows the quantitative evaluation of our method and the state-of-the-art methods. Figure 5 shows examples for visual comparison. Our network is superior to the baselines in sketch completion in terms of completion performance and visual results. Compared with Pix2Pix [21], our method produces better results in terms of contour connectedness. DCGAN [40] usually produces blurry sketches. For the two state-of-the-art inpainting methods designed for images, they often produce wrong strokes.
표 5는 우리의 방법과 최첨단 방법의 정량적 평가를 보여줍니다. 그림 5는 시각적 비교를위한 예를 보여줍니다. 우리의 네트워크는 완성 성능 및 시각적 결과 측면에서 스케치 완성의 기준선보다 우수합니다. Pix2Pix [21]와 비교하여 우리의 방법은 윤곽 연결성 측면에서 더 나은 결과를 생성합니다. DCGAN [40]은 보통 흐릿한 스케치를 만듭니다. 이미지 용으로 설계된 두 가지 최첨단 인 페인팅 방법의 경우 종종 잘못된 스트로크를 생성합니다.
4.4. Applications
Incomplete Sketch Recognition. We set our sketch completion as an effective intermediate step to solve the problem of incomplete or corrupted sketch recognition. Sketch completion is conducted before sketch recognition. As mentioned in Section 1, Figure 1 shows the incomplete sketch recognition process with and without our sketch completion as an intermediate step.
4.4. 응용 불완전한 스케치 인식.
스케치 완성은 불완전하거나 손상된 스케치 인식 문제를 해결하기위한 효과적인 중간 단계로 설정했습니다. 스케치 인식 전에 스케치 완성이 수행됩니다. 섹션 1에서 언급했듯이 그림 1은 스케치 완료가 중간 단계로 포함되거나 포함되지 않은 불완전 스케치 인식 프로세스를 보여줍니다.
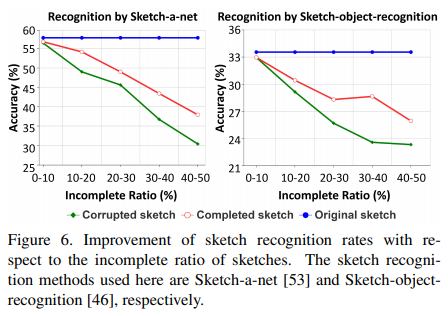
Moreover, we have found that the improvement of sketch recognition rate is largely influenced by the incomplete ratio of the corrupted data. When the incomplete ratio is relatively low, the current sketch recognition methods can cope with such input data quite robustly, but these methods cannot maintain the same level of performance as the incomplete ratio increases. In such cases, our sketch completion helps improve the recognition performance significantly. Here we conduct an incomplete sketch recognition experiment using two well-known sketch recognition methods: Sketch-a-net [53] and Sketch-object-recognition [46]. Figure 6 shows the sketch recognition performance w.r.t. varying incomplete ratio of sketches, indicating that our incomplete sketch recognition approach is universal for improving general sketch recognition methods. Using our sketch completion method as an intermediate step of the incomplete sketch recognition task can enhance the recognition accuracy significantly, especially for sketches corrupted seriously.
또한, 스케치 인식률 향상은 손상된 데이터의 불완전한 비율에 의해 크게 영향을 받는다는 것을 발견했습니다. 불완전 비율이 상대적으로 낮을 때 현재의 스케치 인식 방법은 이러한 입력 데이터에 매우 강력하게 대처할 수 있지만 이러한 방법은 불완전 비율이 증가함에 따라 동일한 수준의 성능을 유지할 수 없습니다. 이러한 경우 스케치 완성은 인식 성능을 크게 향상시키는 데 도움이됩니다. 여기서 우리는 잘 알려진 두 가지 스케치 인식 방법 인 Sketch-a-net [53]과 Sketch-object-recognition [46]을 사용하여 불완전한 스케치 인식 실험을 수행합니다. 그림 6은 스케치 인식 성능 w.r.t를 보여줍니다. 스케치의 불완전한 비율을 달리하여 불완전한 스케치 인식 접근 방식이 일반적인 스케치 인식 방법을 개선하는 데 보편적임을 나타냅니다. 스케치 완성 방법을 불완전한 스케치 인식 작업의 중간 단계로 사용하면 특히 심각하게 손상된 스케치의 경우 인식 정확도를 크게 향상시킬 수 있습니다.
Sketch Editing. 스케치 편집.

Hand-drawn sketches are usually incomplete in scenarios such as overlapping sketches for a scene with multiple objects, interim sketches, or corrupted sketches due to image segmentation. Neither the well-known sketch2photo problem [7] or the current sketch recognition studies have considered or handled the situations where corrupted sketches are provided, which brings huge obstacles and limitations to post sketching applications. Here we use our sketch completion method as an intermediate step which offers a new mode of sketch applications (See Figure 7).
손으로 그린 스케치는 일반적으로 여러 개체가있는 장면의 겹치는 스케치, 중간 스케치 또는 이미지 분할로 인한 손상된 스케치와 같은 시나리오에서 불완전합니다. 잘 알려진 sketch2photo 문제 [7] 또는 현재의 스케치 인식 연구는 스케치 후 응용 프로그램에 큰 장애물과 한계를 가져 오는 손상된 스케치가 제공되는 상황을 고려하거나 처리하지 않았습니다. 여기서는 스케치 애플리케이션의 새로운 모드를 제공하는 중간 단계로 스케치 완성 방법을 사용합니다 (그림 7 참조).
4.5. User Study
Since pixel level comparisons do not always give meaningful measure of sketch completion quality, we further design user studies to evaluate our sketch completion method.
4.5. 사용자 연구
픽셀 수준 비교가 항상 스케치 완성 품질에 대한 의미있는 측정을 제공하는 것은 아니기 때문에 우리는 스케치 완성 방법을 평가하기 위해 사용자 연구를 추가로 설계합니다.
User Study I. We ask 15 users (8 males and 7 females) to evaluate the naturalness of our sketch completion, since there do not exist standardized criteria to evaluate sketch quality [9]. The mean age of the participants is 24.5 years. Before the experiment, we explained the purpose and procedures to the participants. Each experiment lasted about 15 minutes. In our test, users are shown with randomly selected sketches, either original sketches from the dataset or corrupted sketches completed by our method, and they are asked to evaluate whether the sketch is an actual handdrawn sketch or a completed one. The results show that 38% of our sketch completion results fool the people on average, and 56% of hand-drawn sketches are regarded as hand drawn. This demonstrates that our completed sketches are perceptually close to real hand-drawn sketches from a user perspective.
사용자 연구 I. 스케치 품질을 평가하기위한 표준화 된 기준이 존재하지 않기 때문에 15 명의 사용자 (남성 8 명, 여성 7 명)에게 스케치 완성의 자연 스러움을 평가하도록 요청합니다 [9]. 참가자의 평균 연령은 24.5 세입니다. 실험 전에 참가자들에게 목적과 절차를 설명했습니다. 각 실험은 약 15 분 동안 지속되었습니다. 테스트에서 사용자는 데이터 세트의 원본 스케치 또는 우리의 방법으로 완료된 손상된 스케치 중 무작위로 선택한 스케치를 보여주고 스케치가 실제 손으로 그린 스케치인지 완성 된 스케치인지 평가하도록 요청받습니다. 결과에 따르면 스케치 완성 결과의 38 %는 평균적으로 사람들을 속이고 손으로 그린 스케치의 56 %는 손으로 그린 것으로 간주됩니다. 이것은 완성 된 스케치가 사용자 관점에서 실제 손으로 그린 스케치에 지각 적으로 가깝다는 것을 보여줍니다.
User Study II. Next, we analyze subjective quality judgment of the completed sketches processed by our method and by other image completion methods. We adopt a two alternative force choice (2AFC) scheme which is widely used in psychological studies as it is simple and reliable. 20 participants are asked to pick a better one between the results of our method and those of Pix2Pix or GlobalLocalImageCompletion. Images are shown in random order to avoid bias. The results show that more than 76% and 84% users believe the completion results of our method are better than those completed by Pix2Pix and GlobalLocalImageCompletion, respectively, proving that our method is superior to state-of-the-art methods from a user perspective.
사용자 연구 II. 다음으로, 우리의 방법과 다른 이미지 완성 방법으로 처리 된 완성 된 스케치의 주관적인 품질 판단을 분석합니다. 우리는 간단하고 신뢰할 수 있기 때문에 심리학 연구에서 널리 사용되는 2AFC (two Alternative Force Choice) 방식을 채택합니다. 20 명의 참가자는 우리 방법의 결과와 Pix2Pix 또는 GlobalLocalImageCompletion의 결과 중에서 더 나은 결과를 선택하도록 요청 받았습니다. 이미지는 편향을 피하기 위해 무작위 순서로 표시됩니다. 그 결과 76 %와 84 % 이상의 사용자가 우리 방법의 완료 결과가 각각 Pix2Pix 및 GlobalLocalImageCompletion에 의해 완료된 결과보다 낫다고 믿으며 사용자 관점에서 우리의 방법이 최첨단 방법보다 우수하다는 것을 증명합니다. .
5. Conclusions
In this paper, a novel solution to joint sketch completion and recognition is proposed, and a completion model fusing cascade network and conditional GANs is used to capture the characteristics of sketches. The experiments demonstrate that the proposed model performs very well in various sketch completion tasks, and also demonstrate that sketch completion is useful in various sketch-based applications. Although promising performance has been achieved, there are still many issues open to be addressed in future work, such as coping with different styles of sketches and multiple objects at the same time, etc. In addition, the missing areas of sketches are limited to 50% in our current experiment settings. However, users may draw very rough sketches with fewer and inaccurate strokes on touch screen devices. We will extend the framework to complete sketches with large missing ratio in future.
본 논문에서는 공동 스케치 완성 및 인식에 대한 새로운 솔루션을 제안하고, 스케치의 특성을 포착하기 위해 캐스케이드 네트워크와 조건부 GAN을 융합 한 완성 모델을 사용합니다. 실험은 제안 된 모델이 다양한 스케치 완성 작업에서 매우 잘 수행됨을 보여주고 스케치 완성이 다양한 스케치 기반 응용 프로그램에서 유용함을 보여줍니다. 유망한 성능을 달성했지만, 다른 스타일의 스케치와 여러 개체를 동시에 처리하는 등 향후 작업에서 해결해야 할 문제가 여전히 많이 있습니다. 또한 스케치의 누락 영역은 50 개로 제한됩니다. 현재 실험 설정의 %입니다. 그러나 사용자는 터치 스크린 장치에서 더 적은 수의 부정확 한 스트로크로 매우 대략적인 스케치를 그릴 수 있습니다. 향후 결 측률이 큰 스케치를 완성하도록 프레임 워크를 확장 할 예정입니다.
'비지도학습 > GAN' 카테고리의 다른 글
| Improved Consistency Regularization for GANs , 2020 (0) | 2021.04.21 |
|---|---|
| StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (0) | 2021.04.07 |
| [GauGAN] Semantic Image Synthesis with Spatially-Adaptive Normalization (0) | 2021.03.26 |
| StyleGANv2-ada (0) | 2021.03.22 |
| AdaIN,2017 (0) | 2021.03.11 |


